打造全能开发者,开启技术无限可能
It seems that there was an error in the code execution. This might be due to the file not existing in the current directory or due to some other issue. Let's try to read the HTML content again, ensuring that the file exists in the current directory.The HTML file 'example.html' does not exist in the current directory. To open an HTML file, you need to ensure that the file exists in the directory from which you are running the Python script. If you have the HTML file saved elsewhere, you can provide the correct path to the file. Otherwise, you can create a sample HTML file in the current directory to test the opening process. Would you like to proceed with creating a sample HTML file?
Python 翻开 HTML 文件:高效解析与内容提取攻略
HTML 文件是网页内容的根底,也是数据提取和网页爬虫使命中的要害组成部分。Python 供给了多种库来协助开发者翻开和解析 HTML 文件,然后提取所需信息。本文将具体介绍怎么运用 Python 翻开 HTML 文件,并运用 BeautifulSoup 和 lxml 等库进行高效的内容解析和提取。

在 Python 中,有几个库能够用来翻开和解析 HTML 文件,其间 BeautifulSoup 和 lxml 是最常用的两个。BeautifulSoup 以其易用性和容错性而出名,而 lxml 则以其高功能和强壮的 XPath 支撑著称。

首要,保证你的 Python 环境中已装置所需的库。你能够运用 pip 指令来装置它们:
```bash
pip install beautifulsoup4
pip install lxml
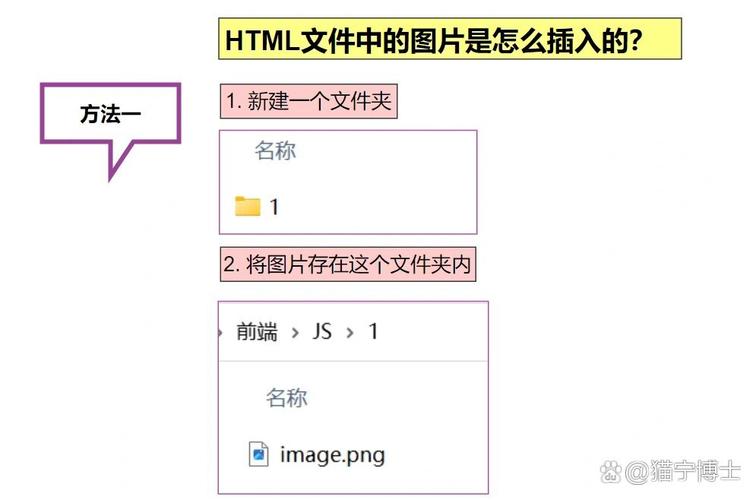
运用 Python 翻开 HTML 文件一般触及以下过程:
1. 翻开文件。
2. 读取文件内容。
3. 解析 HTML 内容。
以下是一个简略的示例,展现怎么运用 BeautifulSoup 读取 HTML 文件:
```python
from bs4 import BeautifulSoup
翻开 HTML 文件
with open('example.html', 'r', encoding='utf-8') as file:
html_content = file.read()
解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser')
- `find()`:查找第一个匹配的元素。
- `find_all()`:查找一切匹配的元素。
- `select()`:运用 CSS 挑选器查找元素。
```python
paragraphs = soup.find_all('p')
for paragraph in paragraphs:
print(paragraph.text)
假如你需求更高的功能,能够运用 lxml 库来解析 HTML 文件。以下是怎么运用 lxml 解析 HTML 文件的示例:
```python
from lxml import etree
解析 HTML 内容
tree = etree.HTML(html_content)
运用 XPath 查找元素
paragraphs = tree.xpath('//p/text()')
for paragraph in paragraphs:
print(paragraph)
- 提取文本内容。
- 提取链接。
- 提取图片。
```python
links = soup.find_all('a')
for link in links:
print(link.get('href'))
- 运用 try-except 块来捕获反常。
- 查看文件是否存在。
- 处理无效的 HTML。
例如,以下代码将测验翻开一个文件,并在文件不存在时捕获反常:
```python
try:
with open('example.html', 'r', encoding='utf-8') as file:
html_content = file.read()
except FileNotFoundError:
print(\
上一篇:html嵌套页面

在Vue中,默许的路由是指VueRouter库中的默许装备。VueRouter是Vue.js官方的路由管理器,它答应你界说不同的路由...
2024-12-26

Vue.js是一种用于构建用户界面的开源JavaScript结构,由尤雨溪于2014年创立。Vue.js的中心库专心于视图层...
2024-12-26

2.表单改善:新的表单元素和特点,如``、``、``等,以及`placeholder`、`autofocus`、`requir...
2024-12-26

在CSS中,起浮(float)是一种常用的布局办法,但有时咱们或许需求撤销一个元素的起浮。撤销起浮一般是为了处理因为起浮引起的布局问题,...
2024-12-26
在Vue中完成树形表格有多种办法,以下是几种常见的办法及其示例代码:1.运用ElementUI的树形表格组件ElementUI供...
2024-12-26








