打造全能开发者,开启技术无限可能
机器学习中的正则化是一种技能,用于避免模型过拟合,即避免模型在练习数据上体现杰出,但在新数据上体现欠安。正则化经过在丢失函数中增加一个赏罚项来完成,这个赏罚项一般与模型的权重相关。
正则化的意图是约束模型权重的值,然后避免模型过于杂乱。正则化技能有多种,其间最常见的是L1正则化和L2正则化。
L1正则化经过在丢失函数中增加权重向量的L1范数来完成,即一切权重绝对值之和。L1正则化倾向于发生稀少的权重向量,即许多权重为零,这在特征挑选中很有用。
L2正则化经过在丢失函数中增加权重向量的L2范数来完成,即一切权重平方和的平方根。L2正则化倾向于发生较小的权重,但不一定为零。L2正则化在许多机器学习算法中都很常见,例如支撑向量机、逻辑回归和神经网络。
除了L1和L2正则化,还有其他正则化技能,例如dropout正则化、数据增强和提早中止等。这些技能能够独自运用,也能够组合运用,以取得更好的模型功能。
正则化是机器学习中一个重要的概念,它能够进步模型的泛化才能,削减过拟合的危险,然后在新的数据上取得更好的体现。
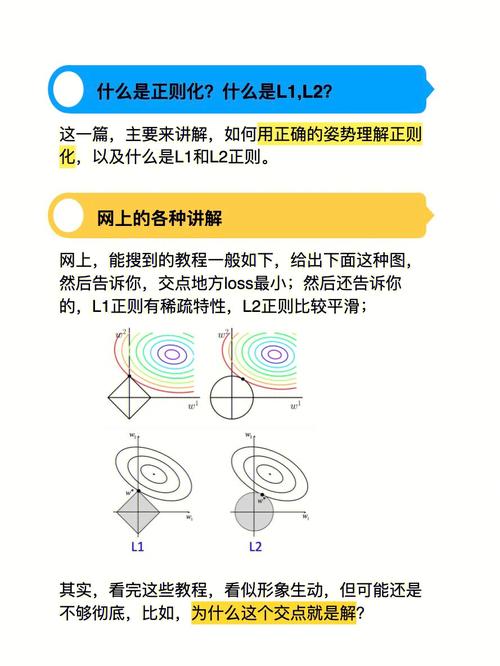
跟着机器学习技能的快速开展,模型杂乱度的增加使得过拟合问题日益突出。过拟合是指模型在练习数据上体现杰出,但在未见过的数据上体现欠安的现象。为了处理这一问题,正则化技能应运而生。本文将介绍机器学习中的正则化办法,讨论其在处理过拟合问题中的使用。
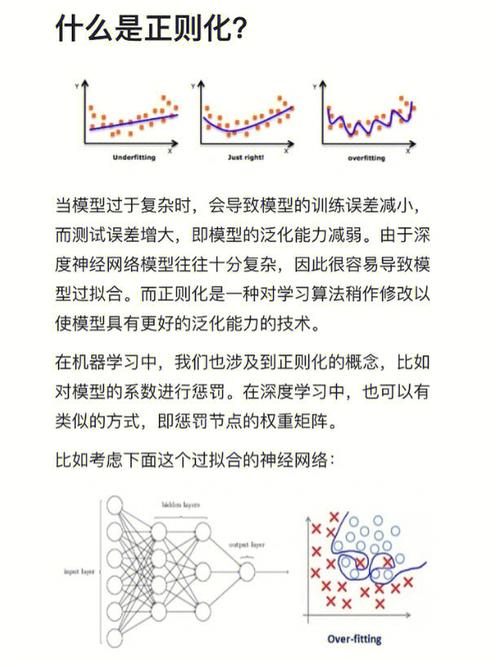
正则化是一种在机器学习模型中增加赏罚项的技能,旨在操控模型杂乱度,避免过拟合。正则化经过约束模型参数的绝对值或平方和,使得模型在练习过程中愈加滑润,然后进步泛化才能。

在机器学习中,常见的正则化办法包含L1正则化、L2正则化和弹性网络正则化等。
L1正则化
L1正则化也称为Lasso正则化,其赏罚项为模型参数的绝对值之和。L1正则化能够将一些参数压缩到零,然后完成特征挑选。
L2正则化
L2正则化也称为Ridge正则化,其赏罚项为模型参数的平方和。L2正则化能够使模型参数愈加滑润,但不会将参数压缩到零。
弹性网络正则化
弹性网络正则化是L1正则化和L2正则化的结合,经过调整两个正则化项的权重,能够一起完成特征挑选和参数滑润。

线性回归
在线性回归中,L1正则化和L2正则化能够用于特征挑选,进步模型的泛化才能。
逻辑回归
逻辑回归模型中,L1正则化和L2正则化能够用于操控模型杂乱度,避免过拟合。
支撑向量机
在支撑向量机中,L1正则化能够用于特征挑选,而L2正则化能够用于操控模型杂乱度。
神经网络
神经网络中,L1正则化和L2正则化能够用于操控网络参数的规划,避免过拟合。
丢失函数增加正则化项
在丢失函数中增加正则化项,如L1或L2赏罚项,能够操控模型杂乱度。
优化算法结合正则化
在优化算法中结合正则化,如梯度下降法,能够一起优化模型参数和正则化项。
正则化参数调整
正则化参数(如正则化强度)的调整关于模型功能至关重要。一般需求经过穿插验证等办法来挑选适宜的正则化参数。
正则化是处理机器学习过拟合问题的有用手法。经过操控模型杂乱度,正则化能够进步模型的泛化才能。本文介绍了正则化的基本概念、类型、使用和完成办法,为读者供给了关于正则化的全面了解。
下一篇: 儿童学习智能机器人,新时代的育儿好帮手

“百变机器学习”实际上是指《百面机器学习》这本书。该书由诸葛越编写,首要涵盖了机器学习范畴的多个方面,旨在协助读者构建一个全面的机器学习...
2024-12-26

神经网络和机器学习是两个密切相关但有所区别的概念。神经网络是一种仿照人脑作业原理的核算模型,由很多彼此衔接的神经元组成。每个神经元接纳输...
2024-12-26

机器学习吴恩达笔记,浅显易懂吴恩达机器学习笔记——敞开AI学习之旅
1.知乎专栏:2.CSDN博客:3.GitHub资源:这些资源涵盖...
2024-12-26

形式辨认与机器学习是两个严密相关但又有差异的范畴。它们都是人工智能的子范畴,致力于让计算机可以从数据中学习并做出决议计划。形式辨认首要重...
2024-12-26

基本概念机器学习是一门多范畴交叉学科,触及概率论、统计学、迫临论、算法杂乱度理论等多门学科。其主要研讨核算机怎么模仿或完成人类的学习行...
2024-12-26









