打造全能开发者,开启技术无限可能
K近邻算法
K近邻算法 是一种简略而强壮的机器学习算法,用于分类和回归问题。它依据这样一个假定:一个样本的类别由其最近的街坊决议。
KNN 作业原理
1. 间隔核算: 关于一个新的样本,核算其与练习会集一切样本的间隔。2. 挑选街坊: 从练习会集挑选与该样本间隔最近的 K 个样本作为街坊。3. 投票/均匀: 依据街坊的类别进行投票,挑选得票最多的类别作为新样本的类别(分类问题)。关于回归问题,则核算街坊的输出值的均匀值作为新样本的猜测值。
KNN 优缺陷
长处:
简略易完成 无需进行参数调整 对异常值鲁棒
缺陷:
核算量大,尤其是 K 值较大时 需求挑选适宜的 K 值 对噪声灵敏
KNN 运用
KNN 算法广泛运用于各种范畴,例如:
图像辨认 文本分类 医疗确诊 引荐体系
KNN 完成示例
以下是一个运用 Python 完成的 KNN 算法示例:
```pythonfrom collections import Counterimport numpy as np
def knn: KNN 算法完成 核算间隔 distances = np.sqrt2, axis=1qwe2qwe2 挑选最近的 K 个街坊 neighbors = np.argsort 获取街坊的类别 neighbor_labels = y_train 投票 label_counts = Counter 回来得票最多的类别 return label_counts.most_common```
KNN 算法是一种简略而强壮的机器学习算法,适用于各种分类和回归问题。尽管它存在一些缺陷,但在许多情况下仍然是一个十分有用的挑选。
深化解析K近邻算法(KNN)在机器学习中的运用

K近邻算法(K-Nearest Neighbors,简称KNN)是一种依据实例的监督学习算法。它经过比较待分类数据点与练习会集一切数据点的间隔,依据间隔最近的K个数据点的类别来猜测待分类数据点的类别。
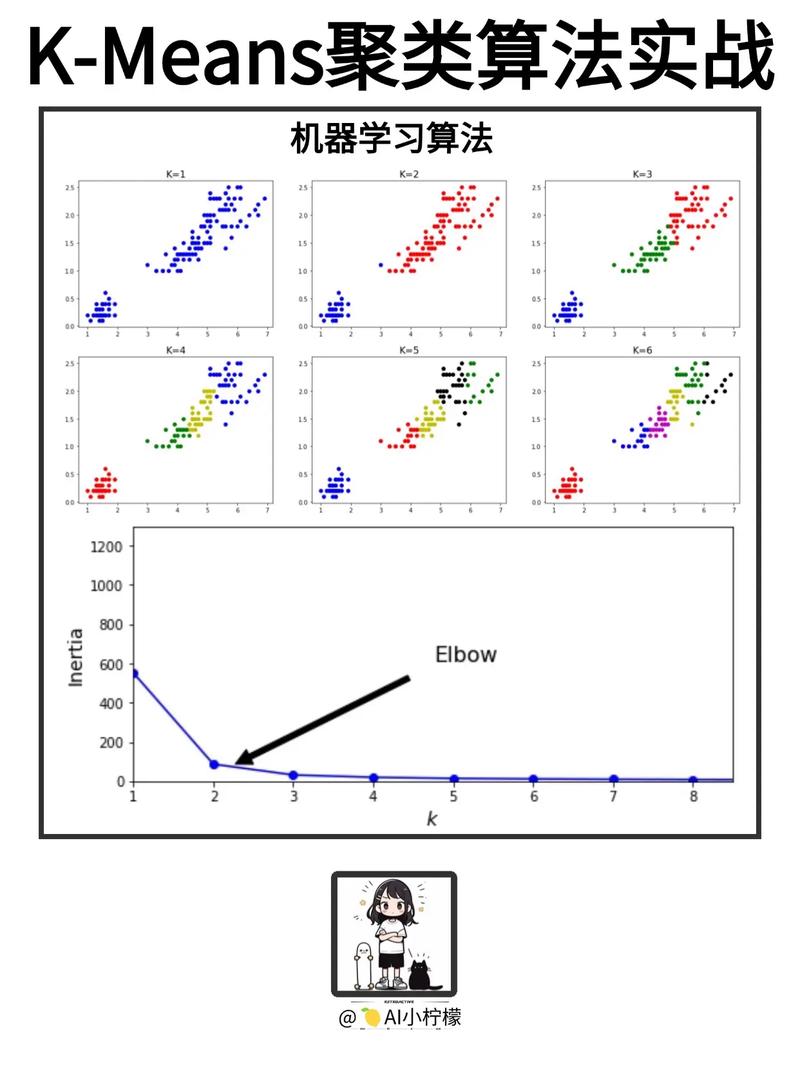
1. 核算间隔:首要,咱们需求核算待分类数据点与练习会集一切数据点之间的间隔。常用的间隔衡量办法有欧氏间隔、曼哈顿间隔、切比雪夫间隔等。
2. 排序:将核算出的间隔依照从小到大的次序进行排序。
3. 挑选K个最近邻:从排序后的间隔中选取间隔最近的K个数据点。
4. 分类决议计划:核算这K个最近邻数据点的类别,并挑选呈现频率最高的类别作为待分类数据点的猜测类别。
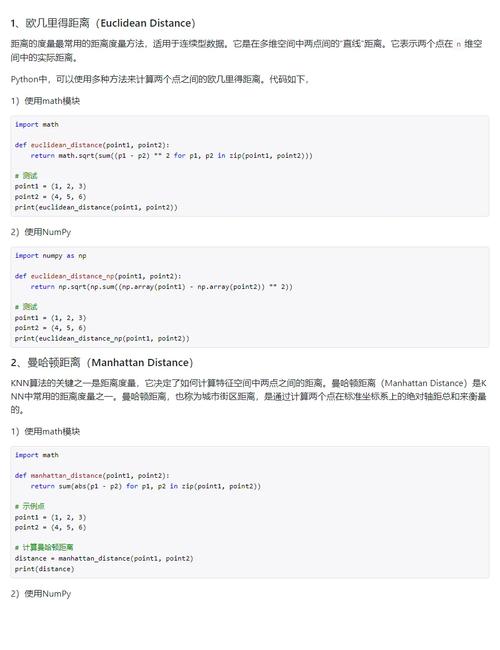
1. 欧氏间隔:欧氏间隔是空间中两点之间的直线间隔,适用于多维空间。其核算公式为:d(x, y) = √(Σ(xi - yi)^2),其间xi和yi别离表明两个数据点在第i维上的值。
2. 曼哈顿间隔:曼哈顿间隔是空间中两点之间的直线间隔,适用于一维空间。其核算公式为:d(x, y) = Σ|xi - yi|,其间xi和yi别离表明两个数据点在第i维上的值。
3. 切比雪夫间隔:切比雪夫间隔是空间中两点之间的最大间隔,适用于多维空间。其核算公式为:d(x, y) = max(|xi - yi|),其间xi和yi别离表明两个数据点在第i维上的值。
1. 经历挑选法:依据经历挑选一个适宜的K值,如K=3、5、7等。
2. 肘部法:经过制作K值与模型准确率之间的联系图,找到准确率产生明显改变的点,该点邻近的K值能够作为参阅。
3. 穿插验证:运用穿插验证办法,经过调整K值,找到最优的K值。
1. 长处:
(1)简略易懂,易于完成。
(2)适用于各种类型的数据,包含数值型和类别型数据。
(3)不需求杂乱的模型练习进程。
2. 缺陷:
(1)核算量大,尤其是当数据集较大时。
(2)对噪声数据灵敏,简略遭到异常值的影响。
(3)K值的挑选对分类成果有较大影响。
1. 图像辨认:K近邻算法能够用于图像辨认使命,如人脸辨认、物体辨认等。
2. 引荐体系:K近邻算法能够用于引荐体系,如电影引荐、产品引荐等。
3. 医疗确诊:K近邻算法能够用于医疗确诊,如疾病猜测、药物引荐等。
K近邻算法是一种简略易懂、易于完成的机器学习算法。它在各种运用场景中都有广泛的运用。K近邻算法也存在一些缺陷,如核算量大、对噪声数据灵敏等。在实践运用中,咱们需求依据具体问题挑选适宜的间隔衡量办法、K值挑选办法,并留意处理噪声数据。

1.《机器学习》:作者:周志华简介:这本书是机器学习范畴的入门教材,涵盖了机器学习根底知识的各个方面,尽量削减数学知识...
2024-12-25

深度学习和机器学习是人工智能范畴的两个重要分支,它们之间既有联络也有差异。以下是它们的首要差异:1.界说和概念:机器学习(Ma...
2024-12-25

GAM(广义加性模型)是一种机器学习模型,它经过组合一系列滑润函数来猜测呼应变量。这些滑润函数能够对错参数的,也能够是参数化的。GAM特...
2024-12-25

关于机器学习讲义,这里有几个不错的资源引荐:1.吴恩达的机器学习课程讲义:吴恩达教师的机器学习课程是机器学习入门的第一课和最抢...
2024-12-25

AI创造免费是一个相对较新的概念,它涉及到运用人工智能技术来生成各种类型的内容,如文本、图画、音乐等,而无需付出任何费用。这种服务一般由...
2024-12-25








