打造全能开发者,开启技术无限可能
SVM(支撑向量机)是一种强壮的机器学习算法,广泛运用于分类和回归问题。以下是SVM的一些基本概念和原理:
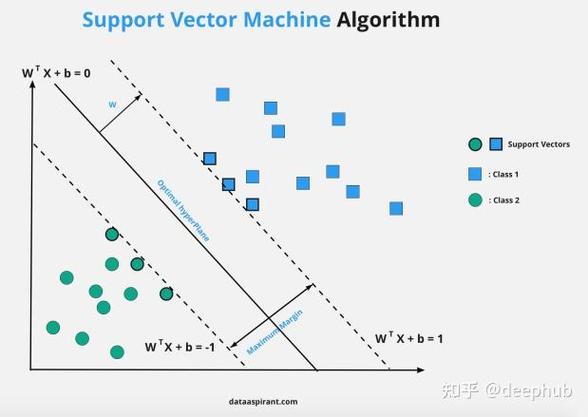
1. 基本思维:SVM的方针是在特征空间中找到一个超平面,将不同类其他数据点分隔,使得这个超平面与最近的数据点(支撑向量)之间的距离最大化。这个超平面被称为最大距离超平面。
2. 线性SVM:当数据是线性可分的时分,SVM能够找到一个线性超平面来分隔不同类其他数据点。这个超平面由支撑向量决议,它们是离超平面最近的点。
3. 非线性SVM:当数据不是线性可分的时分,SVM能够运用核函数(如径向基函数、多项式函数等)将数据映射到一个高维空间,使得在高维空间中数据是线性可分的。
4. 支撑向量:支撑向量是那些离超平面最近的点,它们决议了超平面的方位和方向。在SVM中,只要支撑向量对模型的猜测成果有影响。
5. 软距离:在实际国际中,数据往往不是彻底线性可分的。为了处理这个问题,SVM引进了软距离的概念,答应一些数据点违背距离束缚,可是需求付出必定的价值。
6. 丢失函数:SVM的丢失函数通常是 hinge loss,它衡量数据点与超平面的距离。在软距离SVM中,丢失函数还包含了违背距离束缚的赏罚项。
7. 正则化:在SVM中,正则化项(如 L2 正则化)用于操控模型的复杂度,避免过拟合。正则化项通常是经过调整超参数来完成的。
8. 超参数:SVM的超参数包含正则化参数、核函数参数等。这些参数需求经过穿插验证等办法来挑选,以取得最佳的模型功能。
9. 运用:SVM在许多范畴都有运用,如文本分类、图画辨认、生物信息学等。
10. 长处:SVM具有很好的泛化才能,能够处理高维数据,而且对噪声和异常值有必定的鲁棒性。
11. 缺陷:SVM的核算复杂度较高,特别是当数据量很大或许特征维度很高时。此外,SVM对超参数的挑选比较灵敏,需求细心调整。
总归,SVM是一种强壮的机器学习算法,它能够处理线性可分和非线性可分的数据,而且在许多范畴都有广泛的运用。

支撑向量机(Support Vector Machine,简称SVM)是一种强壮的监督学习算法,广泛运用于分类和回归问题。本文将深化解析SVM的原理、运用场景以及优化办法,协助读者全面了解这一机器学习算法。
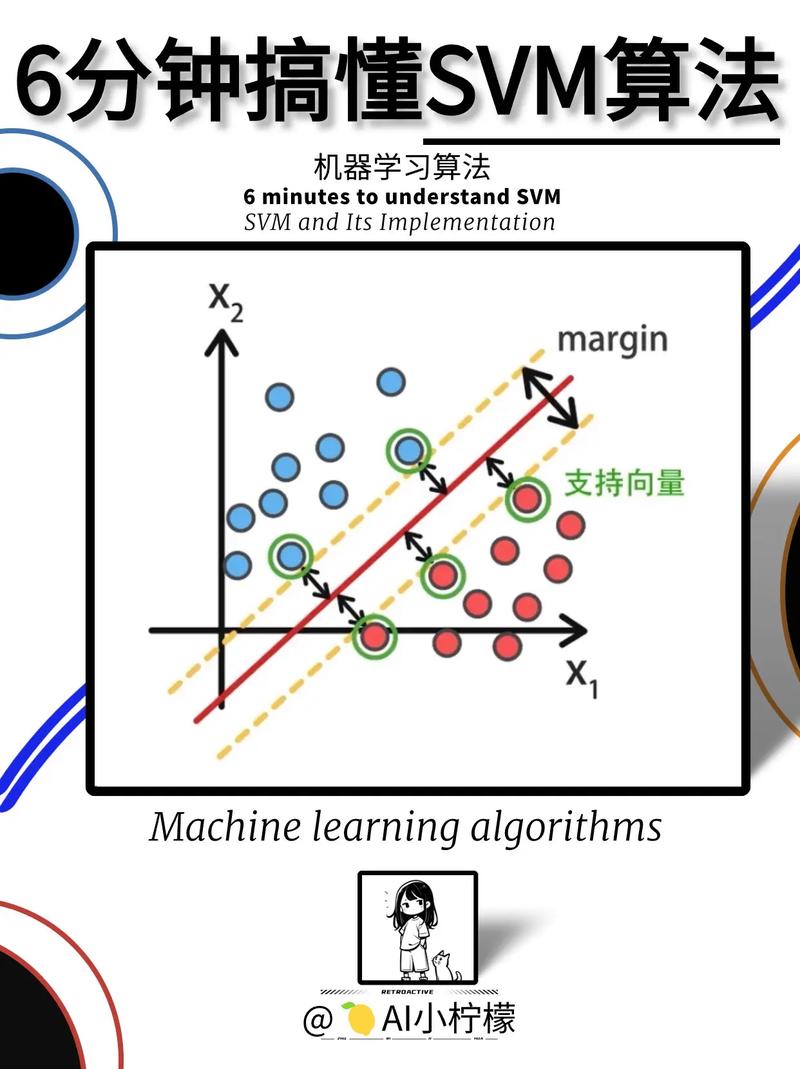
支撑向量机(SVM)的中心思维是经过结构一个超平面(Hyperplane)来将不同类其他数据点分隔,使得类之间的距离最大化。换句话说,SVM企图找到一个最优的决议计划鸿沟,使得不同类其他点在该鸿沟的两边有最大的距离,然后进步分类的准确性和泛化才能。
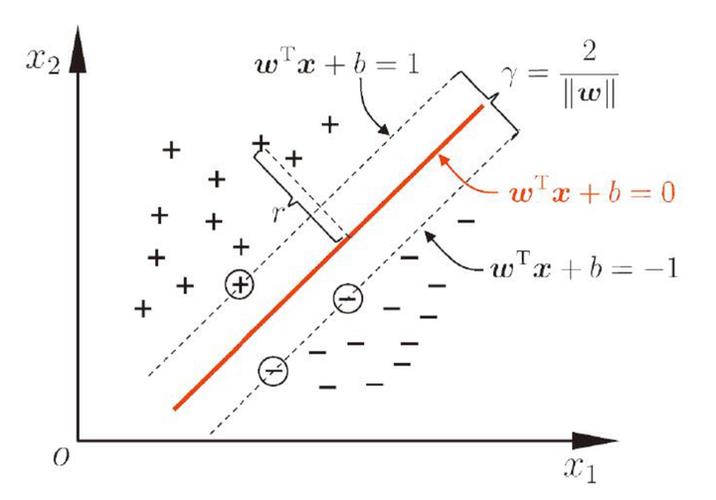
SVM的数学原理根据优化问题,经过最大化分类距离来完成分类。以下将经过数学推导具体介绍其基本原理。


SVM的最优化问题能够表明为以下方式:
其间,w是超平面的法向量,αi是拉格朗日乘子,C是赏罚参数,Σ表明求和。
因为原始问题是一个凸二次规划问题,能够经过引进拉格朗日乘子将其转化为对偶问题。对偶问题的方针函数为:
其间,αi ≥ 0,αj ≥ 0,αk ≥ 0,Σ表明求和。

当数据不行线性切割时,SVM能够经过核函数将数据映射到更高维的空间,使得本来不行分的状况变得可分。常用的核函数包含线性核、多项式核、径向基函数(RBF)核等。
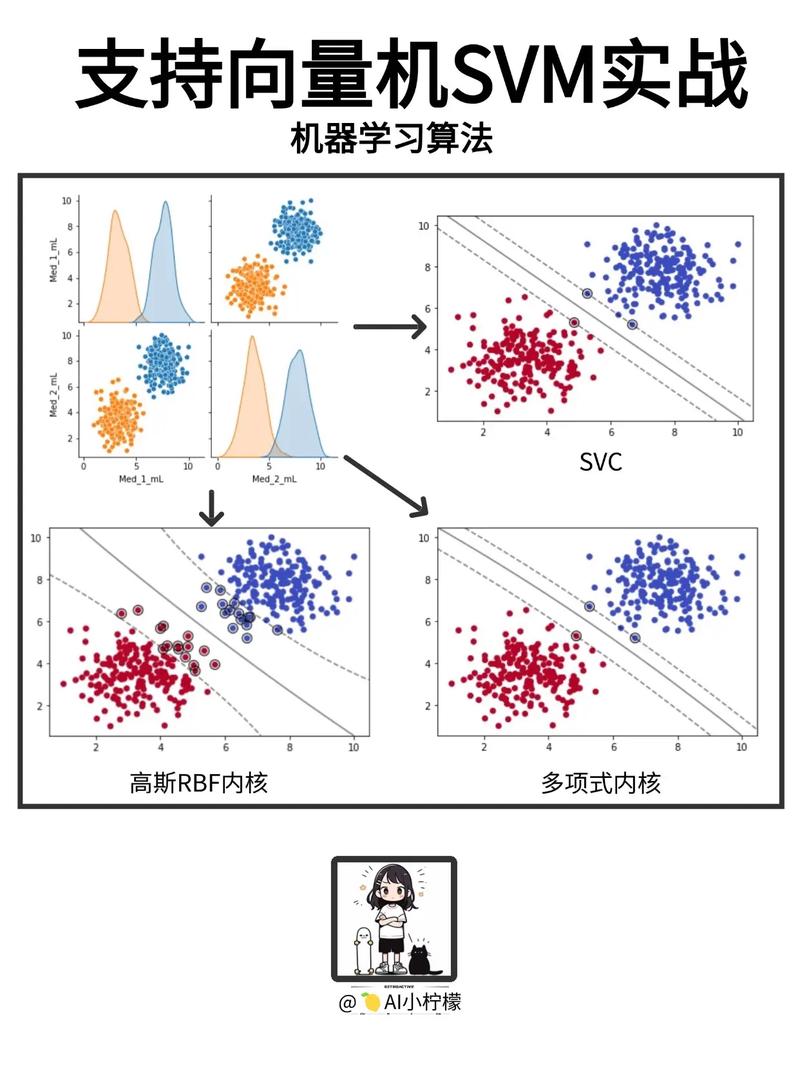
在非线性分类问题中,SVM经过核函数将数据映射到高维空间,然后在这些高维空间中寻觅最优超平面。支撑向量是离决议计划鸿沟最近的样本点,它们决议了超平面的方位。

SVM具有杰出的泛化才能,在许多实际问题中体现出色。以下罗列一些SVM的运用场景:

SVM在图画辨认范畴有着广泛的运用,如人脸辨认、物体辨认、图画分类等。

SVM在文本分类范畴也有着杰出的体现,如垃圾邮件过滤、情感剖析、文本聚类等。
SVM在生物信息学范畴也有着广泛的运用,如基因表达数据剖析、蛋白质结构猜测、疾病诊断等。
SVM在金融猜测范畴也有着必定的运用,如信誉评分、股票市场猜测、危险操控等。

SVM的优化问题是一个非凸问题,直接求解较困难。以下罗列一些常用的SVM优化办法:
梯度下降法是一种常用的优化办法,经过迭代更新参数来迫临最优解。
支撑向量机(SVM)是一种强壮的监督学习算法,在许多实际问题中体现出色。本文深化解析了SVM的原理、运用场景以及优化办法,期望对读者

您好,请问您详细想了解哪方面的AI官网信息?例如,假如您想了解百度AI敞开途径,能够拜访。假如您有其他特定的需求,请告诉我,我会极力为您...
2024-12-29

什么是屠戮机器学习?屠戮机器学习是指运用机器学习技能,使机器具有自主决议计划和履行屠戮的才干。这种技能一般触及以下几个方面:方针...
2024-12-29

AI的生长归纳点评是一个杂乱的问题,由于AI的生长涉及到多个方面,包含技能开展、使用车开展,促进AI技能的立异和使用。6.国际协作:A...
2024-12-29

AI模型归纳是指将多个AI模型组合在一起,以完成更杂乱、更强壮的功用。这种归纳可以包含不同类型的模型,例如将深度学习模型与传统的机器学习...
2024-12-29

1.工业规划与技能立异到2023年6月,我国人工智能中心工业规划现已到达5000亿元,人工智能企业数量超越4400家,仅次于美国,全...
2024-12-28

2024-12-29 #后端开发

2024-12-29 #后端开发
2024-12-29 #AI

windows没声响,Windows体系忽然没声响?全面解析处理办法
2024-12-29 #操作系统

装备 windows update,处理Windows Update装备失利问题,轻松晋级体系
2024-12-29 #操作系统





