打造全能开发者,开启技术无限可能
1. 数据搜集:搜集需求分类的文本数据。
2. 数据预处理:对文本数据进行清洗、分词、去除停用词、词干提取或词形复原等处理,以削减噪声并进步模型练习功率。
3. 特征提取:将文本转换为机器学习模型能够了解的数值特征。常见的特征提取办法包含TFIDF、Word2Vec、GloVe等。
4. 模型挑选与练习:挑选适宜的机器学习算法(如朴素贝叶斯、支撑向量机、随机森林、神经网络等)并运用练习数据对模型进行练习。
5. 模型评价:运用验证集或测验集对模型进行评价,以确认模型的功能。
6. 模型调优:依据评价成果调整模型参数或测验不同的算法,以进步模型功能。
7. 模型布置:将练习好的模型布置到出产环境中,用于对新的文本数据进行分类。
8. 继续学习:跟着新数据的不断发生,能够对模型进行继续学习,以进步模型的适应性和准确性。
文本分类在许多范畴都有广泛的运用,如垃圾邮件过滤、情感剖析、主题分类、客户服务主动呼应等。跟着自然言语处理技能的开展,文本分类算法也在不断进步,以更好地了解和处理人类言语。
机器学习文本分类:技能解析与运用实践
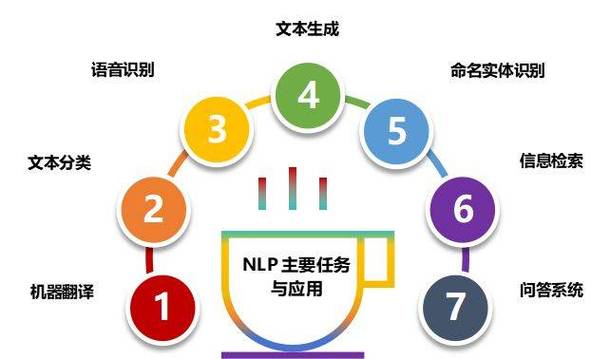


文本分类是指将文本数据依照必定的规矩和算法,主动分配到预界说的类别中。其方针是经过算法模型,完成对很多文本数据的主动分类,进步信息处理的功率。



情感剖析是文本分类的一种运用,旨在剖析文本中的情感倾向,如正面、负面或中立。

垃圾邮件过滤是文本分类的另一个运用,经过剖析邮件内容,将垃圾邮件与非垃圾邮件进行分类。

信息检索是文本分类的一个重要运用,经过将文本数据分类,进步信息检索的功率。
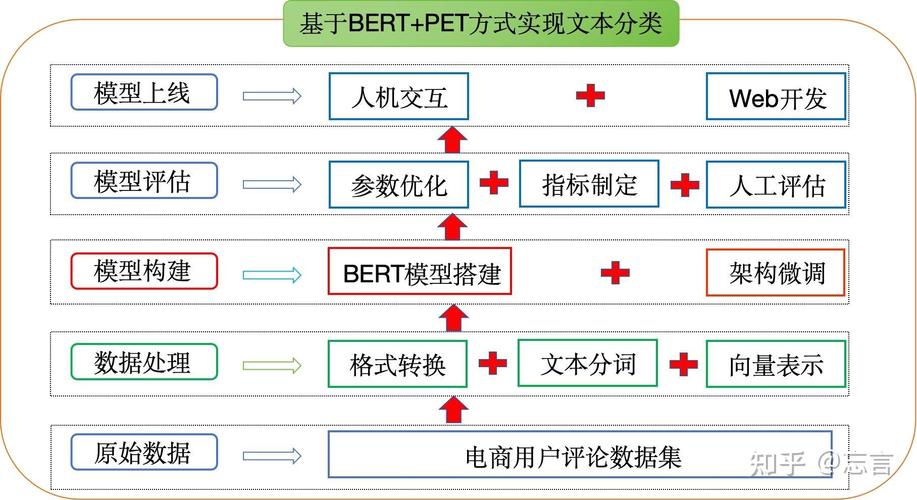
在进行文本分类之前,需求对文本数据进行预处理,包含去除停用词、分词、词性标示等。
挑选适宜的文本分类模型,对预处理后的文本数据进行练习,并运用测验集对模型进行评价。
依据评价成果,对模型进行优化,进步分类准确率。将模型布置到实践运用中。
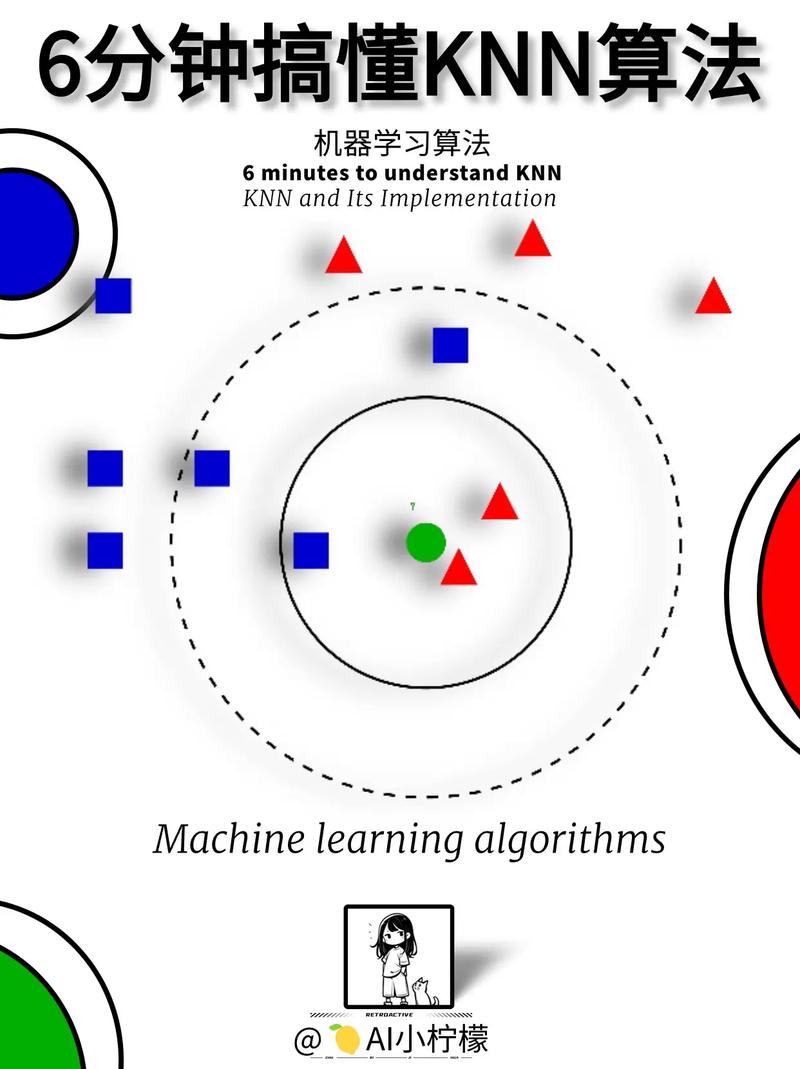
跟着深度学习技能的不断开展,文本分类技能也在不断进步。未来,文本分类技能将在更多范畴得到运用,如智能客服、智能引荐等。

虽然文本分类技能在不断开展,但仍面对一些应战,如数据不平衡、噪声数据等。跟着技能的不断进步,这些应战也将逐步得到解决。
经过本文的介绍,信任我们对机器学习文本分类有了更深化的了解。在实践运用中,挑选适宜的文本分类办法,结合数据预处理、模型练习与评价等过程,能够有效地完成文本分类使命。

机器学习在线课程引荐1.吴恩达的“机器学习”公开课渠道:Coursera言语:英语,供给中文字幕特色:...
2024-12-30
机器学习小样本问题是指在运用机器学习算法时,数据集的样本数量十分有限的状况。在传统的大数据年代,机器学习算法一般依赖于很多的数据来练习模...
2024-12-30
1.图画辨认与分类:运用深度学习模型,如卷积神经网络(CNN),对图画进行分类,如辨认手写数字、动物、植物等。2.文本剖析:运用自然...
2024-12-30
1.英语学习软件:许多英语学习软件都使用了AI技能,如智能语音辨认、自然言语处理和机器学习,来协助用户进步英语听、说、读、写才能。例如...
2024-12-30

AI艺术字一般指的是运用人工智能技能来规划和生成具有艺术感的字体。这种技能可以主动生成一起、构思和特性化的字体,为规划师供给更多挑选和构...
2024-12-30








