打造全能开发者,开启技术无限可能
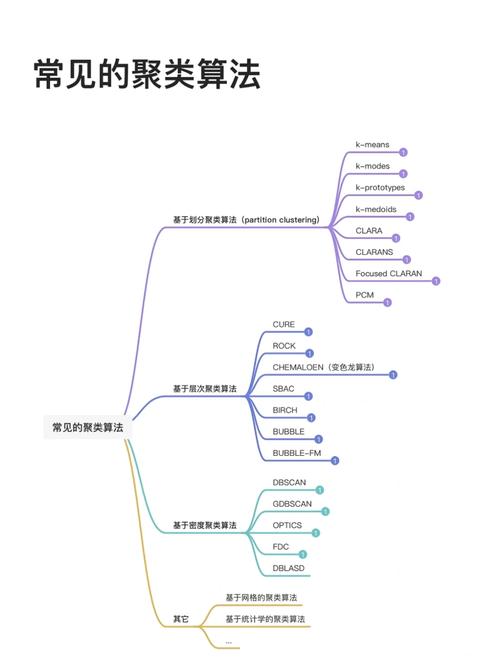
大数据聚类算法有很多种,它们首要分为以下几类:
1. 依据区分的办法:这类算法将数据集区分为若干个不相交的子集,每个子集是一个簇。常见的算法有Kmeans算法和Kmedoids算法。2. 依据层次的办法:这类算法经过一系列的兼并或割裂操作,将数据集区分为一个层次结构的簇。常见的算法有层次聚类算法和二叉树聚类算法。3. 依据密度的办法:这类算法将数据集区分为若干个密度相连的簇。常见的算法有DBSCAN算法和OPTICS算法。4. 依据网格的办法:这类算法将数据空间区分为若干个网格单元,每个网格单元是一个簇。常见的算法有STING算法和CLIQUE算法。5. 依据模型的办法:这类算法将数据集区分为若干个模型生成的簇。常见的算法有高斯混合模型(GMM)和隐马尔可夫模型(HMM)。
此外,还有一些其他的聚类算法,如依据谱的办法、依据神经网络的办法等。
在挑选聚类算法时,需求考虑数据的特色和聚类的意图。例如,关于高维数据,或许需求挑选依据密度的办法或依据模型的办法;关于动态数据,或许需求挑选依据层次的办法或依据区分的办法。
1. Kmeans算法:简略易完成,但需求预先指定簇的数量,对噪声和异常值灵敏。2. Kmedoids算法:对噪声和异常值不灵敏,但核算复杂度较高。3. 层次聚类算法:可以发生层次结构的簇,但核算复杂度较高。4. DBSCAN算法:可以处理恣意形状的簇,对噪声和异常值不灵敏,但需求预先指定邻域半径和最小邻域点数。5. OPTICS算法:可以处理恣意形状的簇,对噪声和异常值不灵敏,而且可以发生层次结构的簇,但核算复杂度较高。6. STING算法:可以处理大规模数据集,但需求预先指定网格巨细。7. CLIQUE算法:可以处理高维数据集,但需求预先指定簇的维度。8. 高斯混合模型(GMM):可以处理恣意形状的簇,但对噪声和异常值灵敏。9. 隐马尔可夫模型(HMM):可以处理时刻序列数据,但对噪声和异常值灵敏。
以上信息仅供参考,详细挑选哪种聚类算法需求依据实践情况进行评价。
跟着大数据暴降的到来,数据量呈爆破式增加,怎么有效地对海量数据进行处理和剖析成为了一个重要课题。聚类算法作为一种无监督学习办法,在数据发掘、模式辨认等范畴有着广泛的使用。本文将介绍几种常见的大数据聚类算法,并剖析它们的优缺点。
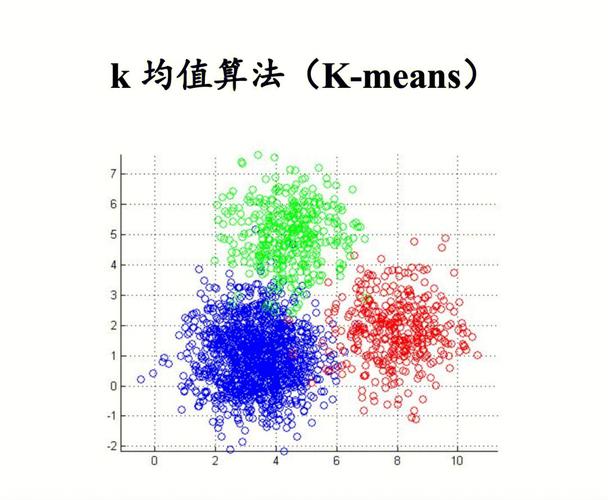
K-means算法是一种经典的聚类算法,其中心思维是将数据集区分为K个簇,使得每个簇内的数据点尽或许挨近,而簇与簇之间的数据点尽或许远。K-means算法的过程如下:
初始化:随机挑选K个数据点作为初始聚类中心。
分配数据点:核算每个数据点到各个聚类中心的间隔,将数据点分配到间隔最近的聚类中心地点的簇。
更新聚类中心:核算每个簇中所稀有据点的均值,作为新的聚类中心。
重复过程2和3,直到聚类中心不再发生变化或到达预设的迭代次数。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法是一种依据密度的聚类算法,它将具有满意高密度的区域区分为簇,一起可以辨认出噪声点。DBSCAN算法的过程如下:
确认邻域半径ε和最小样本数minPts。
关于每个数据点,查看其邻域内是否包括至少minPts个数据点。
假如满意条件,则将该数据点及其邻域内的数据点区分为一个簇。
关于剩下的数据点,重复过程2和3,直到所稀有据点都被分配到簇或被标记为噪声点。
层次聚类算法是一种依据层次结构的聚类办法,它将数据集逐渐兼并或割裂,构成一棵聚类树。层次聚类算法的过程如下:
将每个数据点视为一个簇。
核算一切簇之间的间隔,挑选间隔最近的两个簇兼并为一个簇。
重复过程2,直到所稀有据点兼并为一个簇或到达预设的层数。
层次聚类算法可以分为凝集式聚类和割裂式聚类两种类型。凝集式聚类从单个数据点开端,逐渐兼并,而割裂式聚类则相反,从一个大簇开端,逐渐割裂。
密度聚类算法是一种依据数据点密度的聚类办法,它将具有高密度的区域区分为簇。常见的密度聚类算法有OPTICS(Ordering Points To Identify the Clustering Structure)算法和HDBSCAN(Hierarchical Density-Based Spatial Clustering of Applications with Noise)算法等。
OPTICS算法是一种改善的DBSCAN算法,它经过引进一个参数α来平衡聚类质量和噪声点的辨认。HDBSCAN算法则是一种依据层次结构的密度聚类算法,它可以主动确认簇的数量,并辨认出恣意形状的簇。
大数据聚类算法在数据发掘、模式辨认等范畴有着广泛的使用。本文介绍了K-means、DBSCAN、层次聚类和密度聚类等几种常见的大数据聚类算法,并剖析了它们的优缺点。在实践使用中,应依据详细问题和数据特色挑选适宜的聚类算法。

空间数据库办理体系(SpatialDatabaseManagementSystem,简称SDBMS)是一种用于办理地舆空间数据的数...
2025-01-06

数据库的业务(Transaction)是数据库办理体系履行进程中的一个逻辑单位,它由一系列操作组成,这些操作要么悉数完结,要么悉数不履行...
2025-01-06

长途拜访数据库一般触及以下几个过程:1.确认数据库类型和版别:了解你想要长途拜访的数据库类型(如MySQL、PostgreSQL、SQ...
2025-01-06

大数据办理与运用是一个触及多个范畴的专业,首要重视怎么有效地搜集、存储、处理和剖析很多数据,以便从中提取有价值的信息和洞悉。以下是该专业...
2025-01-06

大数据剖析(BigDataAnalytics)是指从很多、杂乱的数据会集提取有价值信息的进程。这些数据集一般包含结构化、半结构化和非...
2025-01-06








