打造全能开发者,开启技术无限可能
MySQL中去除重复数据一般有以下几种办法:
1. 运用 `DISTINCT` 关键字:`DISTINCT` 关键字能够用于 `SELECT` 句子中,用来回来仅有的值。
```sqlSELECT DISTINCT column1, column2, ... FROM table_name;```
2. 运用 `GROUP BY` 句子:`GROUP BY` 句子能够依据一个或多个列对成果集进行分组,每组回来一个记载。
```sqlSELECT column1, column2, ... FROM table_name GROUP BY column1, column2, ...;```
3. 运用 `HAVING` 子句:`HAVING` 子句能够用来过滤分组后的成果。
```sqlSELECT column1, column2, ... FROM table_name GROUP BY column1, column2, ... HAVING condition;```
4. 运用 `ROW_NUMBER` 窗口函数:`ROW_NUMBER` 能够为成果会集的每一行分配一个仅有的序号,一般用于分页或许去重。
```sqlSELECT FROM OVER as rn FROM table_nameqwe2 tWHERE t.rn = 1;```
5. 运用暂时表或许子查询:你能够创立一个暂时表或许子查询来存储不重复的记载,然后从该暂时表或子查询中查询数据。
```sqlCREATE TEMPORARY TABLE temp_table ASSELECT DISTINCT column1, column2, ... FROM table_name;
SELECT FROM temp_table;```
或许运用子查询:
```sqlSELECT FROM as subquery;```
6. 运用 `UNION` 操作符:`UNION` 操作符能够用来兼并两个或多个 `SELECT` 句子的成果集,并主动去除重复的记载。
```sqlSELECT column1, column2, ... FROM table_name1UNIONSELECT column1, column2, ... FROM table_name2;```
请留意,`UNION` 会主动去除重复的记载,而 `UNION ALL` 不会去除重复的记载。
挑选哪种办法取决于你的详细需求和数据结构。在实践运用中,或许需求结合多种办法来到达最佳作用。

在MySQL数据库办理中,数据去重是一个常见且重要的使命。去重能够保证数据的精确性和一致性,防止重复记载带来的问题。本文将详细介绍MySQL数据库中去除重复数据的办法和技巧。

在数据库中,重复数据或许由于多种原因发生,如数据录入过错、数据导入过错、数据更新过错等。重复数据的存在或许会导致以下问题:
数据冗余,占用额定存储空间。
影响查询功能,由于数据库需求处理更多的数据。
导致数据剖析成果不精确。

MySQL供给了多种内置函数,能够协助咱们辨认和删去重复数据。
1. 运用DISTINCT关键字
DISTINCT关键字能够用来挑选不重复的记载。以下是一个简略的比如:
SELECT DISTINCT column_name FROM table_name;
2. 运用GROUP BY句子
GROUP BY句子能够用来对数据进行分组,并挑选每个组中的仅有记载。以下是一个比如:
SELECT column_name FROM table_name GROUP BY column_name;
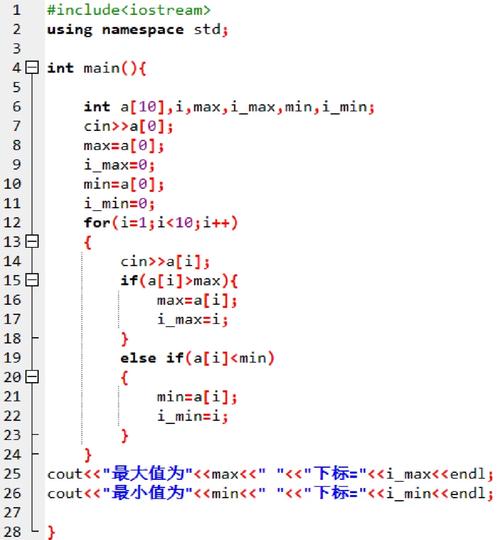
有时候,咱们或许需求先辨认出重复数据,然后再进行删去。这时,能够运用暂时表或变量来辅佐操作。
1. 运用暂时表
创立一个暂时表,将去重后的数据刺进到暂时表中,然后替换原表数据。以下是一个比如:
CREATE TEMPORARY TABLE temp_table AS
SELECT DISTINCT FROM original_table;
REPLACE original_table
SELECT FROM temp_table;
2. 运用变量
运用变量来存储去重后的数据,然后进行替换。以下是一个比如:
SET @row_count = (SELECT COUNT() FROM original_table);
DELETE FROM original_table WHERE id NOT IN (
SELECT id FROM original_table GROUP BY id HAVING COUNT() = 1
UPDATE original_table SET id = @row_count WHERE id IS NULL;
触发器能够在数据刺进或更新时主动履行去重操作。以下是一个比如,演示如安在刺进数据时主动去重:
DELIMITER //
CREATE TRIGGER prevent_duplicates
BEFORE INSERT ON original_table
FOR EACH ROW
BEGIN
DECLARE duplicate_count INT;
SET duplicate_count = (SELECT COUNT() FROM original_table WHERE column_name = NEW.column_name);
IF duplicate_count > 0 THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Duplicate entry';
END IF;
END;
DELIMITER ;

在进行数据去重操作时,需求留意以下几点:
备份原始数据,以防操作失误导致数据丢掉。
在履行删去操作之前,保证现已辨认出一切重复数据。
关于杂乱的去重逻辑,主张先在测验环境中进行验证。
MySQL数据库去重是数据库办理中的一个重要环节。经过运用MySQL内置函数、暂时表、变量和触发器等办法,能够有用去除重复数据,进步数据质量和查询功能。在实践操作中,应依据详细需求和场景挑选适宜的办法。

1.压力测验:经过模仿很多并发用户拜访数据库,测验数据库在高负载状况下的安稳性和呼应时刻。常用的压力测验东西有JMeter、Load...
2025-01-09

晚清民国期刊全文数据库首要分为两个部分:晚清期刊全文数据库和民国时期期刊全文数据库。1.晚清期刊全文数据库:录入规模:1833...
2025-01-09

数据库四大特性一般指的是原子性(Atomicity)、一起性(Consistency)、阻隔性(Isolation)和持久性(Durab...
2025-01-09

sql server 创立数据库,SQL Server 创立数据库的具体攻略
在SQLServer中创立数据库是一个相对简略的进程。以下是创立数据库的根本过程:1.翻开SQLServerManagem...
2025-01-09

数据库体系工程师考试纲要首要包含计算机体系常识、数据库技能、数据库体系规划、开发与办理等多个方面。以下是具体内容:一、考试阐明1.考...
2025-01-09








