打造全能开发者,开启技术无限可能
1. Faiss:由Facebook AI Research开发,是一个用于高效类似性查找和密布向量聚类的库。Faiss支撑多种向量索引办法,包含IVF(Index Value File)和SQ(Scalar Quantization)等。
2. Annoy:由Spotify开发,是一个用于近似最近邻查找(ANN)的库。Annoy运用随机投影树(Random Projection Tree)来加快最近邻查找。
3. Elasticsearch:虽然Elasticsearch首要用于全文查找,但它也支撑向量字段,可以用于向量查找。Elasticsearch运用Lucene作为其底层查找引擎,支撑多种查询类型,包含向量查找。
4. Milvus:由Zilliz开发,是一个高性能、可扩展的向量查找引擎。Milvus支撑多种向量索引办法,包含LSH(Locality Sensitive Hashing)和IVF等。
5. ScaNN:由Google开发,是一个用于大规模最近邻查找的库。ScaNN运用多种技能来加快最近邻查找,包含随机投影和量化等。
6. Qdrant:一个开源的向量数据库,用于存储和查找高维向量。Qdrant支撑多种向量索引办法,包含LSH、IVF和SQ等。
7. Weaviate:一个开源的向量查找引擎,用于存储和查找高维向量。Weaviate支撑多种向量索引办法,包含LSH、IVF和SQ等。
8. Vespa:由Yahoo开发,是一个用于大规模查找和引荐的引擎。Vespa支撑向量查找,并供给了多种向量索引办法。
9. Dense Vector Search:由LinkedIn开发,是一个用于大规模最近邻查找的库。Dense Vector Search运用多种技能来加快最近邻查找,包含随机投影和量化等。
10. Vearch:一个开源的向量查找引擎,用于存储和查找高维向量。Vearch支撑多种向量索引办法,包含LSH、IVF和SQ等。
这些向量存储数据库各有其特色和优势,挑选合适的数据库取决于详细的运用场景和需求。
向量存储数据库:构建高效语义查找的柱石
跟着大数据年代的到来,信息量的爆破式增加使得传统的数据库技能难以满意高效检索的需求。向量存储数据库作为一种新式的数据库技能,凭仗其强壮的语义查找才能,成为了构建高效信息检索体系的要害。本文将讨论向量存储数据库的原理、运用场景以及未来发展趋势。

向量存储数据库是一种依据向量空间模型的数据库,它将数据以向量方法存储,并经过核算向量之间的间隔来衡量数据之间的类似度。这种数据库一般用于处理高维数据,如文本、图画、音频等。
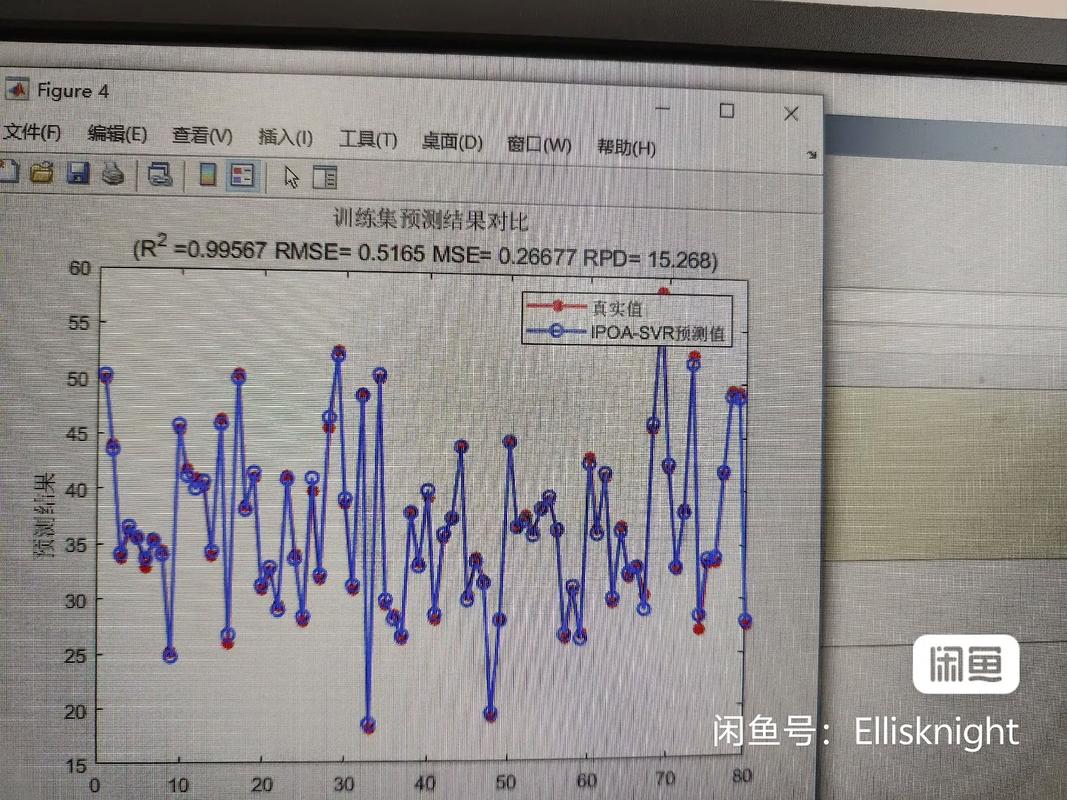
向量存储数据库的中心原理是将数据转换为向量,并存储在数据库中。以下是向量存储数据库的根本过程:


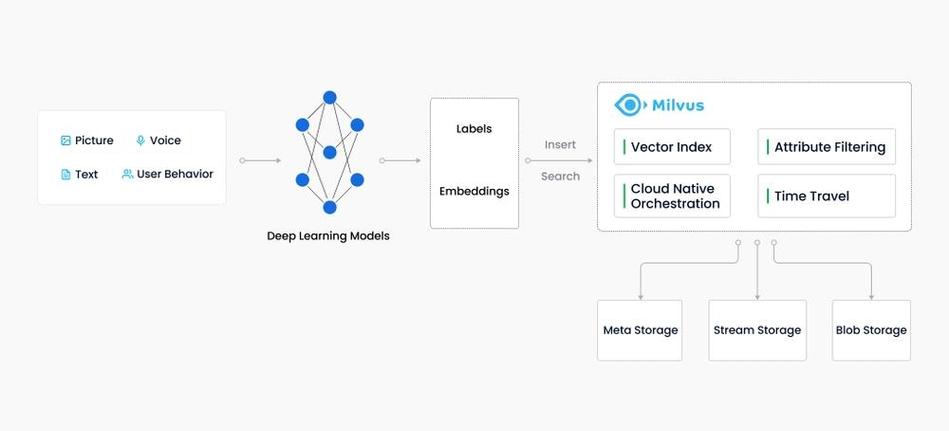




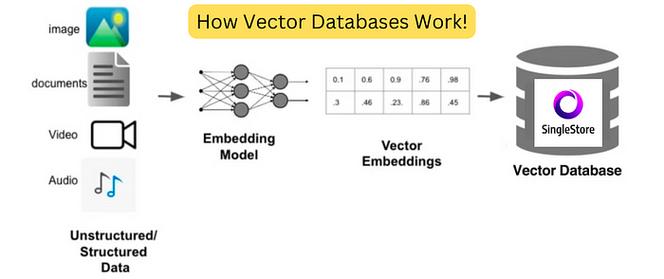
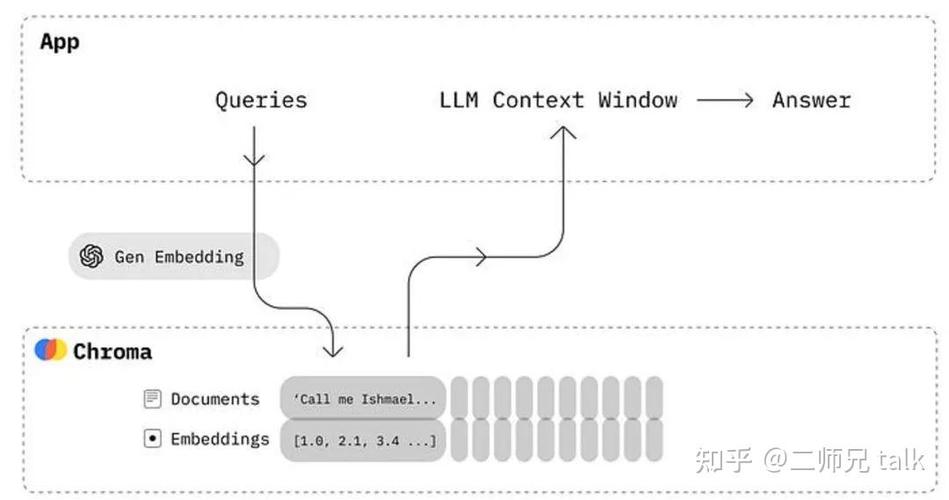
与传统的数据库比较,向量存储数据库具有以下优势:

虽然向量存储数据库具有许多优势,但也面临着一些应战:
跟着技能的不断发展,向量存储数据库将出现以下发展趋势:
向量存储数据库作为一种新式的数据库技能,在信息检索范畴具有广泛的运用远景。经过本文的介绍,信任读者对向量存储数据库有了更深化的了解。跟着技能的不断发展,向量存储数据库将在未来发挥更大的效果。

1.查看仅有键束缚:保证你测验刺进的数据项不与表中现有的任何值抵触。能够运用以下指令来查看表的结构和仅有键束缚:``...
2025-01-10

statNBA数据库是一个专心于NBA数据的中文网站,供给了全面的NBA历史数据和计算信息。以下是关于statNBA数据库的一些详细信息...
2025-01-10
在Linux上装置MySQL能够依照以下进程进行:1.确认你的Linux发行版:不同的Linux发行版(如Ubuntu、CentOS、...
2025-01-10
大数据一词最早出现在20世纪90年代,由多个范畴的专家和学者一起提出。其间,闻名的数据科学家维克托·迈尔舍恩伯格(ViktorMaye...
2025-01-10

依据查找成果,以下是关于国产数据库概念股的详细信息:1.我国软件(600536)主经营务:归纳IT服务最新财政数据:2023年第...
2025-01-10





