打造全能开发者,开启技术无限可能
在Java中,有几种盛行的爬虫结构能够协助开发者高效地抓取网页数据。以下是几种常用的Java爬虫结构:
1. Jsoup:Jsoup是一个用于解析HTML文档的Java库。它供给了一个十分便利的API,能够让你轻松地提取和操作HTML元素。Jsoup能够解析HTML文档,运用CSS挑选器来查找和提取数据,还能够操作HTML元素。它十分合适于那些需求从网页中提取特定信息的运用程序。
2. HtmlUnit:HtmlUnit是一个“无头”的阅读器,它答应你像用户相同阅读网页,而无需发动实践的阅读器。HtmlUnit能够模仿用户的操作,如点击链接、填写表单等,然后获取动态生成的网页内容。它十分合适于那些需求模仿用户行为的爬虫使命。
3. WebMagic:WebMagic是一个简略易用的Java爬虫结构。它供给了许多常用的爬虫功用,如URL办理、页面下载、页面解析、数据存储等。WebMagic还支撑多线程和分布式爬虫,能够让你更高效地抓取很多数据。
4. Heritrix:Heritrix是一个强壮的、可扩展的Web爬虫,它由互联网档案馆(Internet Archive)开发。Heritrix能够抓取整个网站或特定的网站部分,并支撑多种存储格局。它十分合适于那些需求抓取很多网页数据的使命。
5. Selenium:尽管Selenium首要用于自动化测验,但它也能够用于爬虫。Selenium能够模仿用户的操作,如点击链接、填写表单等,然后获取动态生成的网页内容。它十分合适于那些需求模仿用户行为的爬虫使命。
6. Apache Nutch:Apache Nutch是一个高度可扩展、可装备的Web爬虫。它供给了许多高档功用,如URL过滤、内容提取、链接解析等。Apache Nutch还支撑多种存储格局,并能够与其他东西集成。
7. Scrapy:尽管Scrapy是一个Python爬虫结构,但它也能够与Java集成。你能够运用Scrapy来编写爬虫逻辑,然后运用Java来处理爬取的数据。Scrapy供给了许多高档功用,如恳求调度、数据清洗、数据存储等。
这些结构各有优缺点,你能够依据自己的需求挑选适宜的结构。

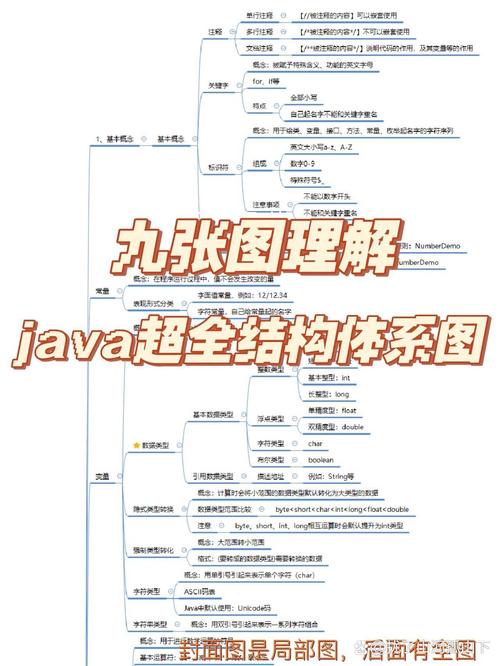
Java爬虫结构是指根据Java言语开发的爬虫东西,它能够协助开发者快速构建爬虫程序,完成数据的抓取、解析和存储。常见的Java爬虫结构有Jsoup、HttpClient、Crawler4j、WebMagic等。
在挑选Java爬虫结构时,需求考虑以下要素:
1. 简略易用
关于初学者来说,挑选一个简略易用的结构能够下降学习本钱,快速上手。Jsoup和WebMagic都是简略易用的结构,合适入门级开发者。
2. 功用丰厚
一个功用丰厚的结构能够满意各种爬虫需求。Jsoup、HttpClient和WebMagic都供给了丰厚的API,支撑多种数据解析、存储和爬虫办理功用。
3. 功能安稳
爬虫程序需求长期运转,功能安稳是挑选结构的重要目标。Crawler4j和WebMagic都支撑多线程抓取,功能较为安稳。
4. 社区活泼
一个活泼的社区能够供给丰厚的学习资源和解决方案。Jsoup、HttpClient和WebMagic都有较为活泼的社区,能够便利开发者解决问题。

以下以Jsoup和WebMagic为例,介绍Java爬虫结构的实战运用。
1. Jsoup爬虫实战
Jsoup是一个根据DOM的HTML解析器,能够便利地提取网页中的数据。以下是一个简略的Jsoup爬虫示例:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupCrawler {
public static void main(String[] args) {
try {
// 获取网页内容
Document document = Jsoup.connect(\
下一篇: 日本1919go go

Bee东西是一个用于快速开发Beego项目的指令行东西。经过Bee东西,你可以轻松地进行Beego项目的创立、热编译、开发、测验和布置。...
2025-01-09

`sqrt`函数是C言语中的一个数学函数,用于核算一个非负数的平方根。它界说在``头文件中。`sqrt`函数的原型如下:``...
2025-01-09

Python是一种解说型、面向对象、动态数据类型的高档程序设计言语。运转Python代码一般需求遵从以下过程:1.装置Pyth...
2025-01-09

《Go!公主光之美少女》(Go!プリンセスプリキュア)是一部由东映动画制造的日本魔法动画,于2015年2月1日起在日本朝日系列电视台...
2025-01-09

《PokemonGo懒人版》是一款十分便当的版别,合适那些没有时刻出门抓精灵的玩家。以下是关于这款游戏的下载和运用办法的具体介绍:...
2025-01-09







