


娱乐吃瓜酱 求三角形,揭秘三角形的魅力与奥秘
亲爱的读者们,今天我要给大家带来一个超级有趣的娱乐八...
2026-06-21
17501
亲爱的读者们,今天我要给大家带来一个超级有趣的娱乐八...

你有没有听说最近娱乐圈又爆出了一个大瓜?这回的瓜可是...

最近有没有被那些娱乐小葱花的明星吃瓜视频刷屏呢?真是...
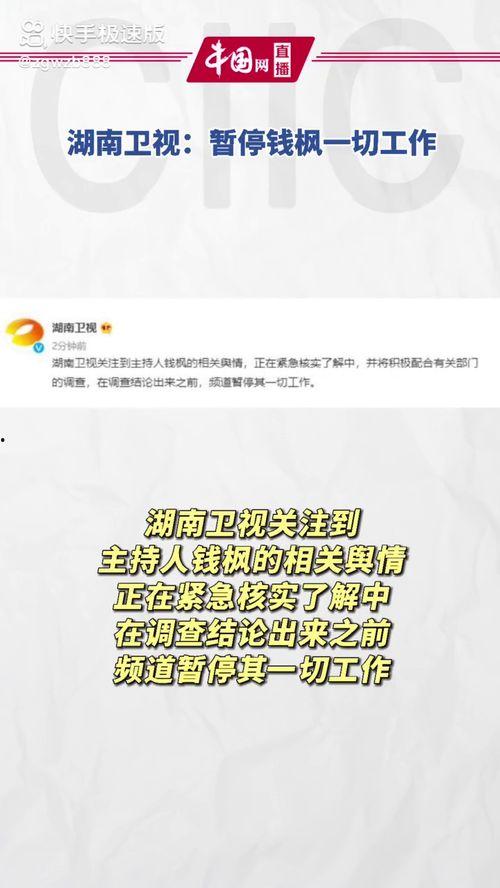
亲爱的读者们,你是不是也和我一样,喜欢在闲暇时刻翻翻...

你知道吗?最近网上有个超级搞笑的潮流——吃瓜比赛搞笑...

2022年的娱乐圈可真是热闹非凡,各种八卦新闻层出不...

说到娱乐吃瓜酱,那可是我青春里的一抹亮色呢!你还记得...

亲爱的读者们,今天我要给你带来一篇超级有趣的娱乐八卦...

你知道吗?最近娱乐圈可是热闹非凡,有一位名叫小蓝姐姐...

你知道吗?最近在网络上掀起了一股“娱乐吃瓜酱语文老师...

17c吃瓜
重温年度最火爆的吃瓜盛宴与精彩瞬间。17c黑料事件真相揭秘:在流量与真相的博弈中,谁才是最后的赢家?