打造全能开发者,开启技术无限可能
大数据根底架构是指支撑大数据搜集、存储、处理、剖析和可视化的技能结构。它包含硬件、软件、网络、数据源等多个组件,旨在高效地处理大规划、多样化、快速改变的数据集。
大数据根底架构的要害组件包含:
1. 数据搜集:搜集来自各种来历的数据,如交际媒体、物联网设备、交易体系等。
2. 数据存储:存储很多数据,一般运用分布式文件体系(如Hadoop HDFS)或NoSQL数据库(如MongoDB、Cassandra)。
3. 数据处理:运用分布式核算结构(如Hadoop MapReduce、Spark)处理和剖析数据。
4. 数据剖析:运用核算办法、机器学习算法和数据剖析东西(如R、Python)来提取洞悉和方法。
5. 数据可视化:将剖析成果以图形和图表的方法出现,以便于了解和决议计划。
6. 数据管理:包含数据质量操控、数据安全和数据管理,保证数据的准确性和合规性。
7. 硬件和网络:包含服务器、存储设备、网络设备和云核算资源,以支撑大数据处理。
8. 数据集成:将来自不同来历的数据集成到一个一致的数据平台上,以便于剖析和查询。
9. 数据拜访:供给API和用户界面,以便于用户拜访和查询大数据。
10. 数据管理:保证数据的质量、安全和合规性,以及数据的运用和同享战略。
大数据根底架构的挑选和规划取决于安排的详细需求和方针,以及数据的规划、杂乱性和速度。跟着大数据技能的不断发展,大数据根底架构也在不断演化和优化,以习惯不断改变的数据处理需求。
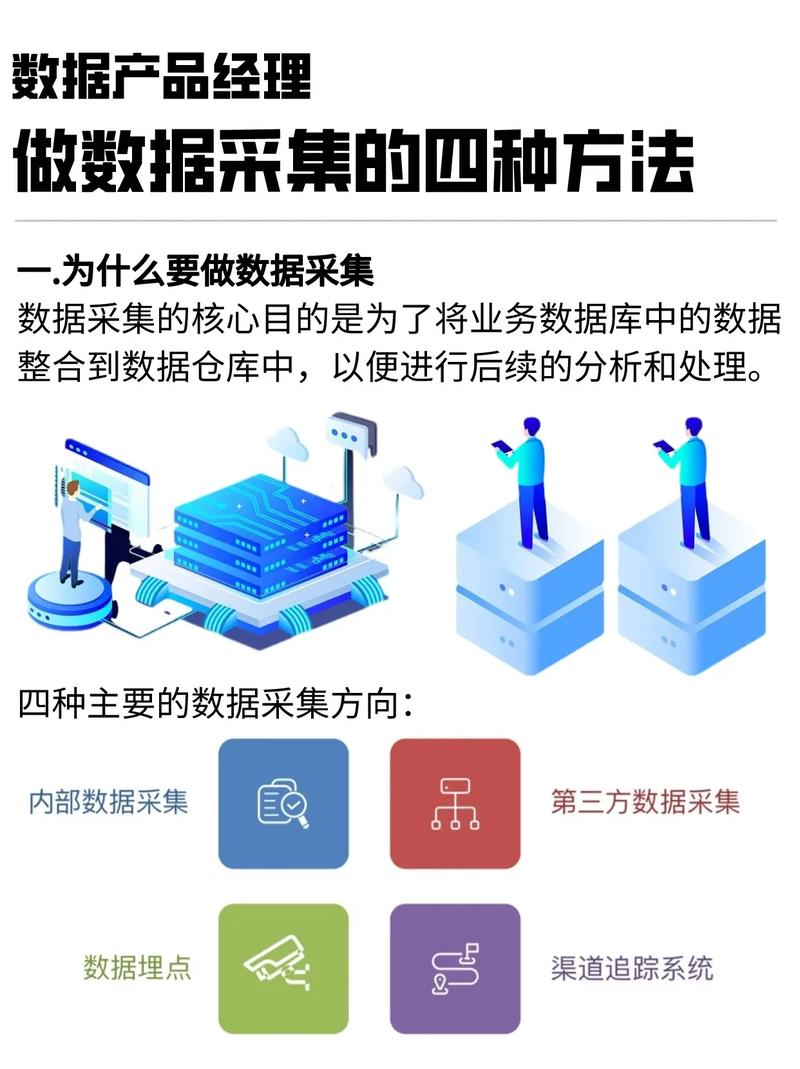
数据搜集是大数据处理的第一步,也是最为要害的一步。数据搜集首要触及以下几种方法:
日志搜集:经过日志体系搜集服务器、应用程序等发生的日志数据。
网络搜集:经过爬虫、API等方法从互联网上获取数据。
传感器搜集:经过传感器设备搜集环境、设备等发生的数据。
数据库搜集:从联系型数据库、NoSQL数据库等数据源中提取数据。

Hadoop HDFS:分布式文件体系,适用于存储海量非结构化数据。
NoSQL数据库:如MongoDB、Cassandra等,适用于存储海量半结构化或非结构化数据。
联系型数据库:如MySQL、Oracle等,适用于存储结构化数据。
数据湖:如Amazon S3、Google Cloud Storage等,供给海量数据的存储和拜访才能。

MapReduce:Hadoop的中心核算结构,适用于大规划数据处理。
Spark:根据内存的分布式核算结构,适用于实时数据处理。
Storm:实时数据处理结构,适用于流式数据处理。
Flink:流处理和批处理结构,适用于杂乱事情处理。

机器学习:经过算法从数据中学习规则,用于猜测、分类、聚类等使命。
数据发掘:从很多数据中发掘出有价值的信息,用于决议计划支撑。
核算剖析:对数据进行核算剖析,提醒数据之间的规则。
可视化:将数据以图形、图表等方法展现,便于了解和剖析。
Tableau:数据可视化东西,支撑多种数据源和图表类型。
Power BI:数据可视化东西,与Microsoft Office集成杰出。
QlikView:数据可视化东西,支撑实时数据剖析和交互。
Python可视化库:如Matplotlib、Seaborn等,适用于Python编程言语。
数据加密:对敏感数据进行加密,避免数据走漏。
拜访操控:约束对数据的拜访权限,保证数据安全。
审计日志:记载数据拜访和操作记载,便于追寻和审计。
数据脱敏:对敏感数据进行脱敏处理,维护个人隐私。
大数据根底架构是支撑大数据处理和剖析的软硬件环境,包含数据搜集、存储、处理、剖析和可视化等环节。跟着大数据技能的不断发展,大数据根底架构也在不断优化和晋级,以满意日益增长的数据处理需求。
上一篇:数据库备份指令,数据库备份概述
下一篇: 数据发掘与大数据的联络,深度解析

CAS数据库是美国化学文摘社(ChemicalAbstractsService,CAS)供给的一系列化学及相关科学范畴的数据库。以...
2025-01-11

大数据智能拓客体系是一种依据大数据技能和人工智能算法的智能化客户获取与拓宽东西,旨在协助企业使用海量数据和智能算法,完结精准营销、高效转...
2025-01-11

关于生猪大数据,你能够参阅以下几个首要渠道和资源:1.国家生猪大数据中心:该渠道供给今天猪价、每日猪讯、工业指数、中心...
2025-01-11

银行在查大数据时,首要重视以下几个方面:1.信誉记载:银行会查询借款人的信誉记载,包含前史借款、信誉卡使用情况、还款记载等。这有助于银...
2025-01-11

1.政务大数据渠道:湖南省政务服务和大数据中心建立了湖南政务大数据大众门户,供给政务数据的揭露和同享服务。2.大数据买卖所:...
2025-01-11








