打造全能开发者,开启技术无限可能
在数据库查询中,去重一般指的是从查询成果中移除重复的记载。这能够经过运用 `SELECT` 句子中的 `DISTINCT` 关键字来完成。`DISTINCT` 关键字会告知数据库只回来查询成果中的仅有记载。
下面是一个简略的比如,假定咱们有一个名为 `students` 的表,其间包括 `id`、`name` 和 `age` 三个字段。假如咱们想要查询一切学生的名字,可是不想看到重复的名字,咱们能够运用如下查询:
```sqlSELECT DISTINCT name FROM students;```
这个查询会回来 `students` 表中一切仅有的学生名字。
假如你想要在多个字段上进行去重,你能够在 `DISTINCT` 后边列出这些字段,例如:
```sqlSELECT DISTINCT name, age FROM students;```
这个查询会回来 `students` 表中一切仅有的名字和年纪组合。
需求留意的是,`DISTINCT` 关键字只能用于 `SELECT` 句子中,而且它只能用于列,不能用于表。假如你想要从查询成果中移除重复的行,你需求运用其他办法,比如在 `WHERE` 子句中运用条件来过滤掉重复的行。

在数据库办理中,数据去重是一个常见且重要的使命。重复数据不只占用额定的存储空间,还或许影响查询功率和数据分析的准确性。本文将详细介绍数据库查询去重的办法和技巧,帮助您高效处理重复数据。

重复数据是指在数据库中存在多个完全相同的记载。这些重复或许因为数据录入过错、数据同步问题或事务逻辑过错等原因发生。

数据库去重首要分为两种办法:依据SQL句子的去重和依据使用程序的去重。


SELECT DISTINCT column_name FROM table_name;
这个句子能够回来指定列中不重复的记载。例如,查询不重复的学生名字:
SELECT DISTINCT sname FROM students;
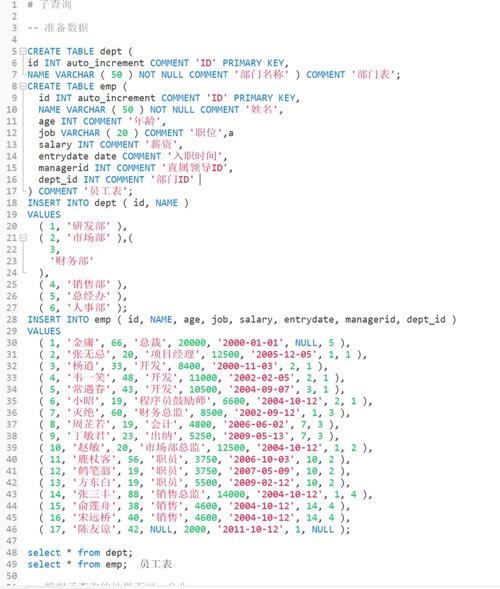
在某些情况下,或许需求对多个列进行去重。这时能够运用分组函数结合HAVING子句来完成。
SELECT column_name FROM table_name GROUP BY column_name HAVING COUNT(column_name) = 1;
例如,查询每个学生名字只呈现一次的记载:
SELECT sname FROM students GROUP BY sname HAVING COUNT(sname) = 1;

子查询也能够用于去重,经过将子查询的成果与主查询的成果进行比照,筛选出重复的记载。
SELECT FROM table_name WHERE id NOT IN (SELECT id FROM table_name GROUP BY id HAVING COUNT(id) > 1);
这个句子会回来一切不重复的记载。

在某些情况下,SQL句子或许无法满意去重需求,这时能够考虑在使用程序层面进行处理。
许多编程言语(如Python、Java等)都供给了处理数据去重的库或函数。经过编程言语能够更灵敏地处理杂乱的数据去重逻辑。

ETL(Extract, Transform, Load)东西能够用于数据清洗和去重。经过ETL东西,能够自动化地处理很多数据,进步去重功率。
在进行数据去重时,需求留意以下几点:

在去重前,保证数据的一致性,防止因数据不一致导致去重过错。

依据实践情况挑选适宜的去重办法,如SQL句子、编程言语或ETL东西。
数据去重或许会对数据库功能发生影响,特别是在处理很多数据时。在去重过程中,留意优化查询句子和数据库装备,以进步功能。
数据库查询去重是数据办理中的重要环节。经过本文介绍的办法和技巧,您能够高效地处理重复数据,进步数据质量和查询功率。在实践使用中,依据详细需求挑选适宜的办法,保证数据去重作业的顺利进行。
上一篇:数据库原理与技能,数据库原理概述

大数据比对一般触及对很多数据进行比较和剖析,以辨认模式、趋势、反常或相关性。具体查些什么鹊记载,以确诊疾病、猜测疾病开展或优化医治计划。...
2025-01-11

我国引文数据库(CCD)是我国知网(CNKI)供给的一个文献引证剖析渠道,旨在协助科研人员和学科建设者进行文献引证的检索、计算和可视化剖...
2025-01-11

MySQL数据库的默许端口是3306。当您在装置MySQL服务器时,假如没有指定其他端口,那么它将默许运用这个端口。在衔接到MySQL服...
2025-01-11

农业大数据渠道是一个综合性的信息渠道,经过运用大数据、物联网、云核算、人工智能等现代信息技能,对农业数据进行搜集、存储、剖析和使用,旨在...
2025-01-11

数据库的三级形式结构是指数据库体系在三个层次上对数据的笼统,这三个层次分别是外形式、概念形式和内形式。这种结构旨在处理数据独立性问题,使...
2025-01-11









