打造全能开发者,开启技术无限可能
MySQL查询去重一般运用`DISTINCT`关键字来完成。`DISTINCT`关键字用于回来仅有不同的值。以下是一个简略的示例:
假定咱们有一个名为`students`的表,其间包括以下字段:
`id`(学生ID) `name`(学生名字) `class`(班级)
假如咱们想要查询一切不同的班级,能够运用以下SQL查询:
```sqlSELECT DISTINCT class FROM students;```
这个查询会回来`students`表中一切不同的班级称号。
假如您有更具体的查询需求或需求进一步的协助,请供给更多的信息。

在数据库办理中,数据重复是一个常见的问题。重复数据不只占用额定的存储空间,还或许影响查询功能和数据分析的准确性。本文将具体介绍MySQL中查询去重的办法,协助您高效处理重复数据。

在MySQL中,运用DISTINCT关键字是去重最直接的办法。DISTINCT关键字能够应用于SELECT句子中,用于回来指定列中不重复的数据。
例如,假定咱们有一个名为`students`的表,其间包括字段`name`和`age`,咱们想要查询去重后的学生名字,能够运用以下SQL句子:
SELECT DISTINCT name FROM students;

GROUP BY和HAVING子句是MySQL中常用的分组聚合函数,也能够用于去重。这种办法特别适用于需求依据某个字段进行分组,并筛选出只呈现一次的数据的状况。
以下是一个示例,假定咱们想要查询`students`表中每个年纪的学生数量,并筛选出只呈现一次的年纪:

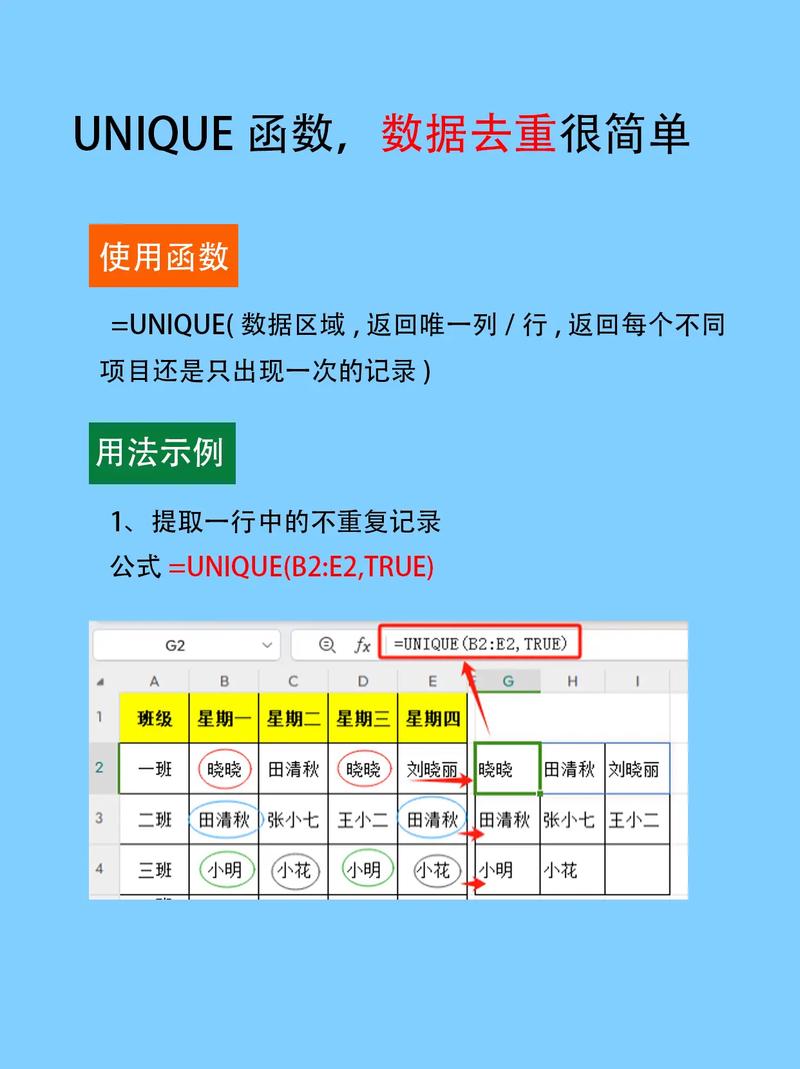
子查询是MySQL中常用的查询办法,也能够用于去重。经过子查询,咱们能够查询出不在子查询中呈现过的数据,然后完成去重。
以下是一个示例,假定咱们想要查询`students`表中不重复的名字,能够运用以下SQL句子:
SELECT name FROM students WHERE name NOT IN (SELECT name FROM students GROUP BY name);

UNIQUE索引能够确保表中的某个字段不重复。在创立表时,能够为需求确保仅有性的字段增加UNIQUE索引。假如表中存在重复数据,MySQL会主动删去重复的记载,只保存其间id最小的记载。
以下是一个示例,假定咱们想要为`students`表中的`name`字段增加UNIQUE索引,能够运用以下SQL句子:
ALTER TABLE students ADD UNIQUE (name);
1. 在运用DISTINCT关键字时,需求留意,假如查询的列包括NULL值,则NULL值也会被去重。
2. 运用GROUP BY和HAVING子句时,假如分组字段包括NULL值,则NULL值会被视为一个分组。
3. 运用子查询去重时,假如子查询中存在重复数据,则或许会影响查询功能。
MySQL供给了多种查询去重的办法,能够依据实际状况挑选适宜的办法。经过合理运用这些办法,能够有用处理重复数据,进步数据库功能和数据分析的准确性。

什么是联系型数据库?联系型数据库(RelationalDatabase)是一种用于存储、办理和检索数据的数据库办理体系。它依据联系模型...
2025-01-16

数据库的三大范式是数据库规划理论中的基本概念,它们辅导着怎么规划一个高效、合理、可扩展的数据库。这三大范式分别是:1.榜首范式(1NF...
2025-01-15

1.全国各地身份证号最初6位数字省市县/区对照表阐明:经过代码能够快速查找归属的省市县/区。2.全国各地行政区划...
2025-01-15

在数据库中,子查询(Subquery)是一种嵌套查询,它答应你在一个查询中包括另一个查询。子查询能够用于SELECT、INSERT、UP...
2025-01-15

关于农业大数据公司,以下是几家公司及其简介:1.布瑞克农业互联网:公司简介:布瑞克农业大数据科技集团有限公司是一家以农业大数据...
2025-01-15






