打造全能开发者,开启技术无限可能
1. 运用大数据查询引擎: Hive:Hive 是一个构建在 Hadoop 之上的数据仓库东西,它能够将结构化的数据文件映射为一张数据库表,并供给简略的 SQL 查询功用,答使用户运用相似 SQL 的言语查询数据。 Presto:Presto 是一个开源的分布式 SQL 查询引擎,它能够在大数据上供给快速的查询才能,支撑多种数据源,如 HDFS、Cassandra、MySQL 等。 Impala:Impala 是 Cloudera 开发的一个 SQL 查询引擎,它能够直接在 Hadoop 集群上履行 SQL 查询,无需将数据移动到其他体系。
2. 运用大数据处理结构: Spark:Apache Spark 是一个快速、通用的大数据处理引擎,它供给了 SQL、流处理、机器学习等多种功用。Spark SQL 答使用户运用 SQL 查询大数据,一起也能够运用 DataFrame API 进行更高档的数据处理。 Flink:Apache Flink 是一个流处理结构,它也支撑批处理和 SQL 查询。Flink 供给了强壮的流处理才能,能够处理实时数据。
3. 运用云服务: Amazon Redshift:Amazon Redshift 是一个快速、可扩展的数据仓库服务,它支撑 SQL 查询,并能够与 AWS 的其他服务(如 S3、DynamoDB)集成。 Google BigQuery:Google BigQuery 是一个彻底保管的大数据查询服务,它支撑规范 SQL 查询,并能够处理 PB 级的数据。
4. 运用 NoSQL 数据库: Cassandra:Cassandra 是一个分布式 NoSQL 数据库,它支撑大规模的数据存储和快速查询。Cassandra 供给了 CQL(Cassandra Query Language),这是一种相似于 SQL 的查询言语。 MongoDB:MongoDB 是一个文档型 NoSQL 数据库,它支撑 JSON 格局的数据存储和查询。MongoDB 供给了 MongoDB Shell 和 MongoDB Compass 等东西,用于履行查询和数据剖析。
5. 运用数据剖析和可视化东西: Tableau:Tableau 是一个数据可视化东西,它支撑衔接到各种数据源,包括大数据渠道。Tableau 答使用户创立交互式仪表板和陈述,以便更好地了解和剖析数据。 Power BI:Power BI 是微软开发的一个商业智能东西,它支撑衔接到各种数据源,包括大数据渠道。Power BI 答使用户创立交互式仪表板和陈述,以便更好地了解和剖析数据。
挑选哪种办法取决于你的具体需求和数据的特色。假如你需求处理结构化数据并履行杂乱的查询,那么运用 SQL 查询引擎或许是一个好挑选。假如你需求处理实时数据或进行流处理,那么运用流处理结构或许更适合你。假如你需求快速查询大数据并创立可视化陈述,那么运用数据剖析和可视化东西或许是一个好挑选。

在当今信息爆破的年代,大数据已经成为企业决议计划、科学研究和社会办理的重要资源。怎么高效地查询和剖析这些海量数据,成为了数据科学家和工程师面对的重要应战。本文将为您具体介绍大数据查询的办法和技巧,帮助您轻松应对大数据年代的应战。
大数据查询是指对海量数据进行检索、挑选和剖析的进程。跟着大数据技术的不断发展,查询办法也日益多样化。以下是几种常见的大数据查询办法:
Spark SQL是Apache Spark生态体系中的一个重要组件,它供给了高效、易用的大数据查询剖析解决方案。以下是Spark SQL的几个中心概念:
DataFrame是以列式格局安排的分布式数据调集,相似于传统数据库中的表。DataFrame供给了丰厚的数据操作API,并支撑运用SQL言语进行查询。DataSet是DataFrame的扩展,供给了类型安全的数据处理才能。
Catalyst是Spark SQL的中心优化器,它担任将用户提交的SQL查询或DataFrame操作转换为高效的物理履行计划。Catalyst经过一系列的优化规矩对查询进行重写和优化,然后进步了查询的履行功率。

ThriftServer是Spark SQL供给的JDBC/ODBC服务器,使得外部使用程序能够经过规范的数据库衔接协议与Spark SQL进行交互。SparkSession是Spark 2.0引进的新概念,它简化了Spark使用程序的创立和装备进程。
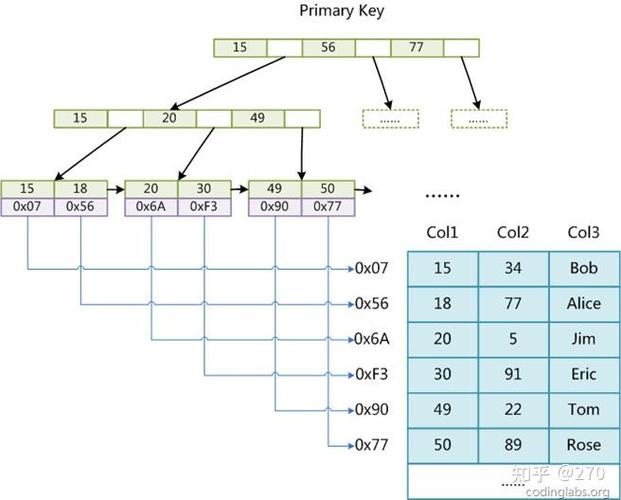
在MSSQL中,为查询中常用的字段和表增加索引是进步查询功用的要害。例如,能够经过以下代码对一个表中的用户名字和暗码字段树立索引:
```sql
CREATE INDEX idxusernamepassword ON user (name, password);
运用子查询能够大大进步MSSQL查询的功率。在查询中运用EXISTS搭配子查询会愈加高效,由于EXISTS只需求回来布尔值,而不需求回来任何其他值。
运用JOIN能够只运用一条SQL句子就能够拉取数据,而不需求多条句子。在MSSQL中运用JOIN或许会使查询的功率更高,由于它能够削减查询的过程,然后节约核算时刻。

在Excel中,能够经过设置查找条件来完成精准查询数据。例如,查找包括特定数值的单元格。

Excel供给了多种快速查找数据值的办法,如条件格局、挑选和排序等。
Google BigQuery是一个云原生的数据仓库服务,能够轻松处理PB等级的数据。以下是BigQuery的一些中心功用:
BigQuery支撑规范SQL和机器学习功用,无需办理硬件或软件,大大简化了大数据剖析的杂乱度。
BigQuery支撑多种数据加载方法,如直接上传文件、运用API导入等。
BigQuery能够与其他东西如Firebase、MySQL等集成,完成更广泛的使用场景。
大数据查询是大数据年代的重要技术。经过把握Spark SQL、MSSQL、Excel和Google BigQuery等东西和技巧,咱们能够高效地处理和剖析海量数据,为企业和个人带来巨大的价值。
下一篇: 大数据剖析结构,大数据剖析结构概述

什么是联系型数据库?联系型数据库(RelationalDatabase)是一种用于存储、办理和检索数据的数据库办理体系。它依据联系模型...
2025-01-16

数据库的三大范式是数据库规划理论中的基本概念,它们辅导着怎么规划一个高效、合理、可扩展的数据库。这三大范式分别是:1.榜首范式(1NF...
2025-01-15

1.全国各地身份证号最初6位数字省市县/区对照表阐明:经过代码能够快速查找归属的省市县/区。2.全国各地行政区划...
2025-01-15

在数据库中,子查询(Subquery)是一种嵌套查询,它答应你在一个查询中包括另一个查询。子查询能够用于SELECT、INSERT、UP...
2025-01-15

关于农业大数据公司,以下是几家公司及其简介:1.布瑞克农业互联网:公司简介:布瑞克农业大数据科技集团有限公司是一家以农业大数据...
2025-01-15






