打造全能开发者,开启技术无限可能
向量数据库的作业原理首要依据向量查找技能,它答应高效地存储和检索高维空间中的数据点。这种数据库类型在处理杂乱数据集,特别是触及图画、音频、文本等非结构化数据的类似性查找时十分有用。以下是向量数据库的一些要害组件和它们的作业原理:
1. 数据表明: 向量数据库中的数据一般表明为高维向量。这些向量可所以原始数据(如文本、图画或音频的嵌入表明)或许经过某种算法(如词嵌入、卷积神经网络或循环神经网络)转化而来的。
2. 索引结构: 向量数据库运用特定的索引结构来高效地存储和检索向量。常见的索引结构包含部分灵敏哈希(LSH)、倒排索引、树状索引(如KD树、球树)等。这些索引结构规划用于快速找到与查询向量最类似的数据点。
3. 类似性衡量: 向量数据库运用类似性衡量来确认向量之间的类似度。常用的类似性衡量包含余弦类似度、欧几里得间隔、曼哈顿间隔等。挑选适宜的类似性衡量取决于详细的运用场景和数据类型。
4. 查询处理: 当用户提交一个查询向量时,向量数据库会运用索引结构来快速定位与查询向量最类似的数据点。这个进程或许触及多个过程,包含向量转化、类似性衡量核算和成果排序。
5. 优化: 为了进步查询功用,向量数据库或许会选用各种优化技能,如批量查询、近似最近邻查找(ANN)和缓存战略。这些优化技能旨在削减核算开支并进步响应速度。
6. 支撑向量运算: 向量数据库一般供给对向量运算的支撑,如向量加法、向量乘法、点积和向量归一化等。这些运算关于许多机器学习和数据剖析使命至关重要。
7. 可扩展性: 向量数据库规划为可扩展的,以便可以处理大规模数据集和杂乱的查询。这或许触及分布式存储、负载均衡和毛病搬运等技能。
8. 多模态支撑: 一些向量数据库支撑多模态数据,这意味着它们可以一起处理不同类型的数据(如图画、文本和音频)。这种才能关于构建杂乱的机器学习模型和数据剖析运用十分有用。
总归,向量数据库经过高效的数据表明、索引结构和类似性衡量技能,为处理高维空间中的数据供给了强壮的支撑。它们在许多范畴,如引荐体系、图画查找、自然语言处理和核算机视觉中发挥着要害作用。
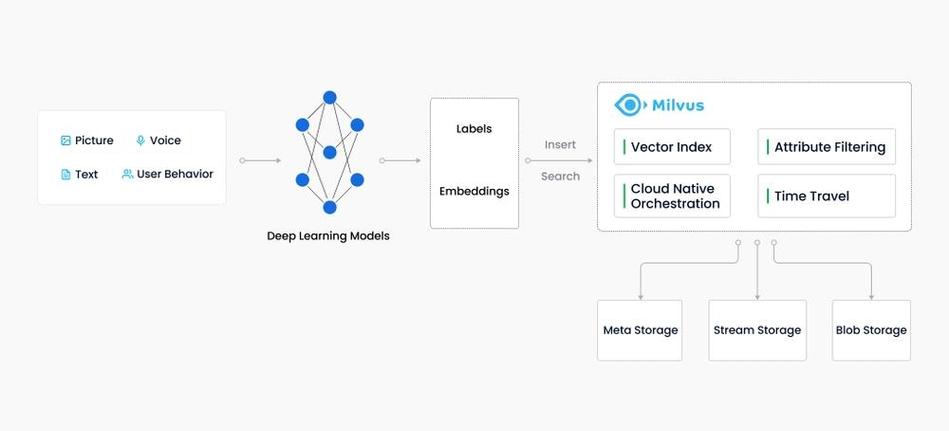
跟着大数据和人工智能技能的快速开展,向量数据库作为一种新式的数据库技能,逐步成为数据存储和检索的重要东西。本文将深入探讨向量数据库的作业原理,协助读者更好地了解这一技能。

向量数据库是一种专门用于存储和检索高维空间中向量数据的数据库。与传统的联系型数据库不同,向量数据库的中心在于对向量数据的存储、索引和查询。它广泛运用于图画辨认、语音辨认、引荐体系等范畴。

向量数据库的作业原理首要包含以下几个过程:
1. 数据存储
向量数据库将向量数据以二进制方式存储在磁盘上。每个向量由多个维度组成,每个维度对应一个特征。例如,一个图画的向量或许包含色彩、形状、纹路等特征。
2. 向量索引
为了进步查询功率,向量数据库需要对向量数据进行索引。常见的索引办法包含:
IVF(Inverted File)索引:将向量数据分红多个簇,经过查询最接近簇的向量来进步查找功率。
LSH(Locality Sensitive Hashing)索引:将向量数据映射到哈希空间,经过比较哈希值来查找类似向量。
FAISS(Facebook AI Similarity Search)索引:一种高效的类似性查找算法,适用于大规模向量数据。
3. 向量查询
向量查询是向量数据库的中心功用。用户可以经过输入一个查询向量,数据库会依据索引办法快速找到与查询向量最类似的向量。常见的查询办法包含:
类似度查询:依据查询向量和数据库中向量的类似度,回来类似度最高的向量。
规模查询:依据查询向量和数据库中向量的间隔,回来间隔在必定规模内的向量。
向量数据库具有以下优势:
高效:向量数据库经过索引和查询优化,可以快速检索类似向量,进步查询功率。
灵敏:向量数据库支撑多种索引和查询办法,可以依据实践需求挑选适宜的计划。
可扩展:向量数据库可以处理大规模向量数据,支撑分布式存储和核算。
向量数据库在以下范畴具有广泛的运用:
图画辨认:经过向量数据库存储和检索图画特征,完成图画分类、物体检测等功用。
语音辨认:将语音信号转化为向量表明,经过向量数据库进行类似度查询,完成语音辨认。
引荐体系:依据用户的前史行为和爱好,经过向量数据库检索类似用户或物品,完成个性化引荐。
自然语言处理:将文本数据转化为向量表明,经过向量数据库进行语义类似度查询,完成文本分类、情感剖析等功用。
向量数据库作为一种新式的数据库技能,在数据存储和检索方面具有明显优势。跟着技能的不断开展,向量数据库将在更多范畴发挥重要作用。
向量数据库, 数据存储, 索引, 查询, 图画辨认, 语音辨认, 引荐体系, 自然语言处理
下一篇: 天刀少女捏脸数据库

一键卸载东西引荐1.OracleDeinstall东西:这是Oracle官方引荐的卸载东西,可以安全、完全地删去Oracl...
2024-12-26

1.MySQL:```sqlCREATEDATABASEdatabase_name;```2.PostgreSQL:```sql...
2024-12-26

数据库工程师需求把握的技能包含:1.数据库根底:了解数据库的基本概念,如数据模型、数据库规划、数据完整性、业务办理等。2.数据库系统...
2024-12-26
删去数据库是一个需求慎重操作的进程,由于一旦删去,数据库中的一切数据将无法康复。以下是删去数据库的一般进程,但请留意,具体的操作或许会依...
2024-12-26

检查数据库端标语的办法取决于你运用的数据库类型。以下是几种常见数据库的检查办法:1.MySQL数据库:在指令行中,你能够运用`...
2024-12-26






