打造全能开发者,开启技术无限可能
决策树是一种常用于分类和回归的机器学习算法。它经过一系列规矩对数据进行切割,以便更好地进行猜测。决策树在许多范畴都有广泛的运用,包含医疗确诊、金融风险评价、市场营销等。
下面是一个运用决策树进行分类的实战事例:
导入必要的库咱们将运用Python的scikitlearn库来构建决策树模型。
加载数据```pythondata = load_irisX = data.datay = data.target```
区分数据集```pythonX_train, X_test, y_train, y_test = train_test_split```
输出成果```pythonaccuracy```
可视化决策树咱们能够运用`graphviz`库来可视化决策树的结构。
```pythonimport graphvizfrom sklearn.tree import export_graphviz
dot_data = export_graphviz graph = graphviz.Source graph```
以上便是一个简略的决策树实战事例。在实践运用中,咱们或许需求调整决策树的参数,如`max_depth`、`min_samples_split`等,以取得更好的功能。
机器学习决策树实战:从理论到实践
决策树是机器学习中一种常用的算法,尤其在分类和回归使命中表现出色。它经过树状结构对数据进行区分,然后完成对数据的猜测。本文将具体介绍决策树的理论基础,并经过一个实践事例展现怎么运用Python进行决策树的实战操作。

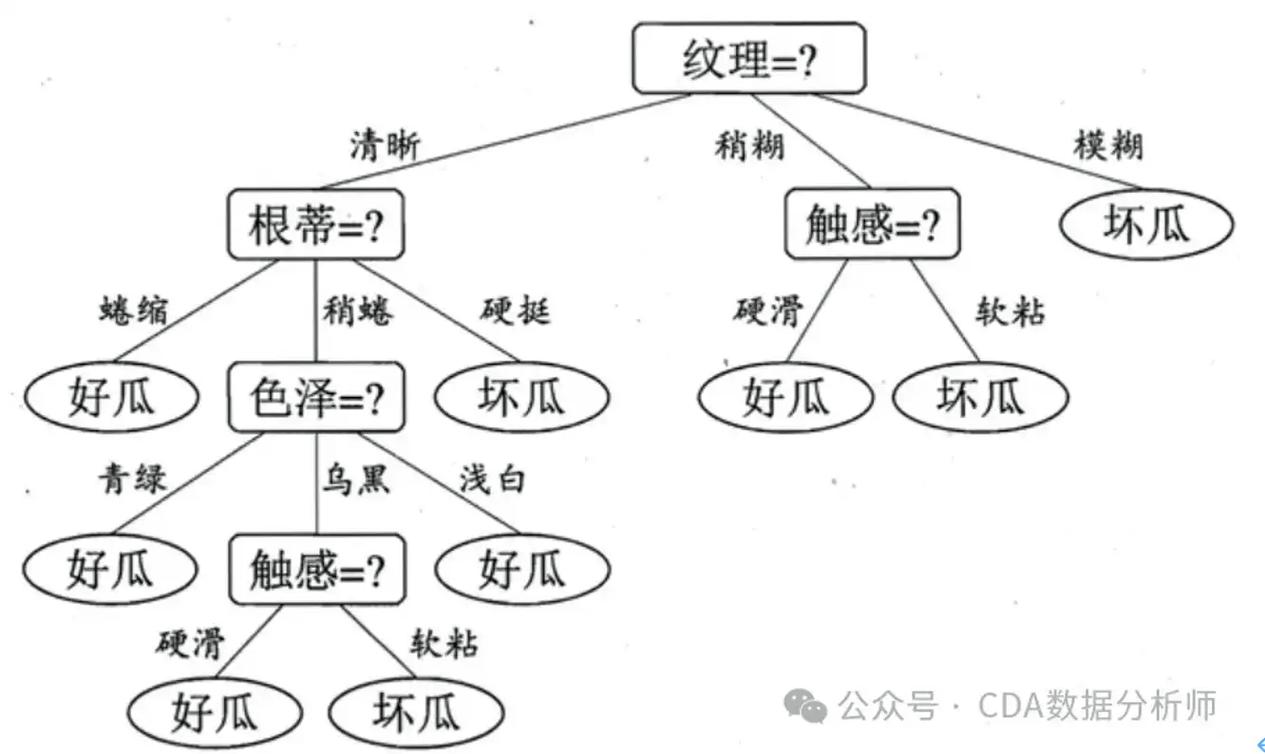
决策树的构建办法首要包含以下几种:
信息增益(ID3算法):经过核算信息增益来挑选最佳区分特征。
基尼指数(CART算法):经过核算基尼指数来挑选最佳区分特征。
增益率:结合信息增益和割裂的节点数来挑选最佳区分特征。
决策树的剪枝办法首要包含以下几种:
预剪枝:在决策树构建过程中,提早中止树的生成,防止过拟合。
后剪枝:在决策树生成后,对树进行剪枝,去除不必要的节点,进步模型的泛化才能。
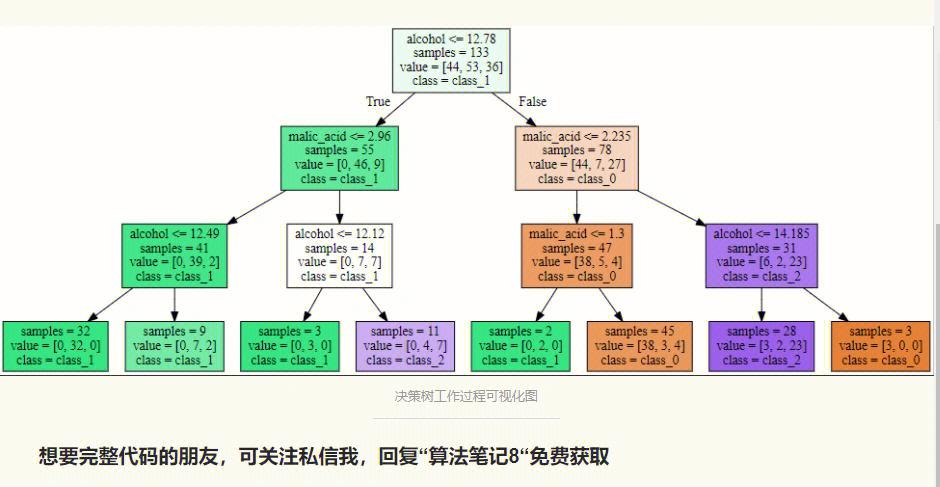
在Python中,咱们能够运用sklearn库中的DecisionTreeClassifier和DecisionTreeRegressor来构建分类和回归的决策树模型。
```python
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
加载数据集
iris = load_iris()
X = iris.data
y = iris.target
区分练习集和测验集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
创立决策树模型
clf = DecisionTreeClassifier(criterion='entropy', max_depth=3)
练习模型
clf.fit(X_train, y_train)
猜测测验集
y_pred = clf.predict(X_test)
评价模型
from sklearn.metrics import accuracy_score
print(\
下一篇: ai怎么裁剪图片,高效快捷的图画处理东西

1.广告范畴:麦当劳与AIGC协作:2023年4月,麦当劳推出了一组由AI与顾客、粉丝一起发明的宣扬广告,这些广告交融了麦当劳...
2024-12-25

基础知识1.界说与概念:如监督学习、无监督学习、强化学习等。2.模型与算法:如线性回归、决策树、支撑向量机、神经网络等。3.评价...
2024-12-25

1.《机器学习》:作者:周志华简介:这本书是机器学习范畴的入门教材,涵盖了机器学习根底知识的各个方面,尽量削减数学知识...
2024-12-25
深度学习和机器学习是人工智能范畴的两个重要分支,它们之间既有联络也有差异。以下是它们的首要差异:1.界说和概念:机器学习(Ma...
2024-12-25

GAM(广义加性模型)是一种机器学习模型,它经过组合一系列滑润函数来猜测呼应变量。这些滑润函数能够对错参数的,也能够是参数化的。GAM特...
2024-12-25









