打造全能开发者,开启技术无限可能
1. Hadoop:Hadoop 是一个分布式核算结构,由 Apache 软件基金会开发。它包含 HDFS(Hadoop Distributed File System)和 MapReduce 两个首要组件。HDFS 用于存储大数据集,而 MapReduce 用于处理这些数据集。
2. Spark:Spark 是一个快速、通用且易于运用的分布式核算体系,由 Apache 软件基金会开发。它支撑多种编程言语,如 Scala、Java、Python 和 R。Spark 供给了多种数据处理功用,包含批处理、流处理、机器学习和图处理。
3. Flink:Flink 是一个开源流处理结构,由 Apache 软件基金会开发。它支撑批处理和流处理,而且具有高吞吐量和低推迟的特色。Flink 供给了丰厚的 API,支撑多种编程言语,如 Java、Scala 和 Python。
4. Kafka:Kafka 是一个分布式流处理渠道,由 Apache 软件基金会开发。它首要用于构建实时数据管道和流使用程序。Kafka 支撑高吞吐量、可扩展性和容错性,而且与多种大数据结构集成。
5. HBase:HBase 是一个分布式、可扩展的、面向列的存储体系,由 Apache 软件基金会开发。它依据 Hadoop 文件体系,供给了对大数据集的随机读写拜访。HBase 适用于需求快速随机拜访大数据集的使用程序。
6. Cassandra:Cassandra 是一个分布式 NoSQL 数据库,由 Apache 软件基金会开发。它具有高可用性、可扩展性和容错性,适用于处理大规模数据集。Cassandra 支撑多种编程言语,如 Java、Python 和 C。
7. Elasticsearch:Elasticsearch 是一个开源查找引擎,由 Elastic 公司开发。它依据 Lucene,供给了快速、精确的全文查找功用。Elasticsearch 适用于处理和剖析大规模文本数据集。
8. Storm:Storm 是一个实时流处理结构,由 Apache 软件基金会开发。它支撑高吞吐量和低推迟的流处理,而且具有容错性和可扩展性。Storm 供给了丰厚的 API,支撑多种编程言语,如 Java、Python 和 Ruby。
这些大数据开源结构在不同的使用场景中具有各自的优势和特色。依据实践需求,能够挑选适宜的结构来处理、存储和剖析大数据集。

Hadoop是由Apache基金会开发的一个开源分布式核算结构,首要用于存储和处理大规模数据集。它包含以下几个中心组件:
HDFS(Hadoop Distributed File System):分布式文件体系,用于存储海量数据。
MapReduce:分布式核算模型,用于处理大规模数据集。
Hive:数据仓库东西,供给相似SQL的查询接口。
HBase:列式存储数据库,适用于存储非结构化和半结构化数据。
Hadoop具有高牢靠性、高扩展性和高吞吐量等特色,适用于处理PB等级的数据。

Spark是Apache基金会开发的一个开源分布式核算引擎,它供给了快速、通用的大数据处理才能。Spark的中心组件包含:
Spark Core:Spark的根底组件,供给分布式使命调度、内存办理等功用。
Spark SQL:供给相似SQL的查询接口,支撑结构化数据存储和处理。
Spark Streaming:实时数据处理结构,支撑高吞吐量的数据流处理。
MLlib:机器学习库,供给多种机器学习算法。
GraphX:图处理结构,支撑大规模图数据的存储和处理。
Spark具有以下特色:
速度快:Spark的内存核算才能使其在处理大数据时比Hadoop快100倍以上。
通用性:Spark支撑多种数据处理场景,包含批处理、实时处理和机器学习。
易用性:Spark供给丰厚的API和东西,便利用户进行大数据开发。
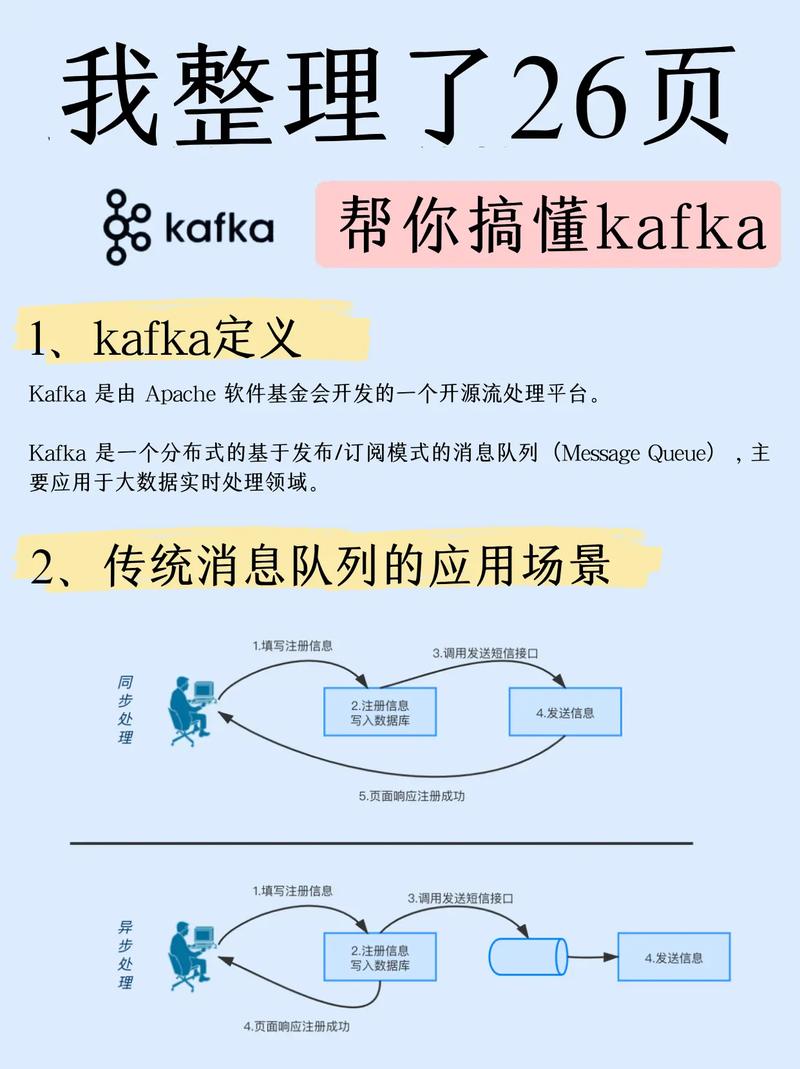
Kafka是由LinkedIn开发的一个开源流处理渠道,首要用于构建实时数据流处理体系。Kafka具有以下特色:
高吞吐量:Kafka能够处理高吞吐量的数据流,适用于处理PB等级的数据。
可扩展性:Kafka支撑水平扩展,能够轻松应对数据量的增加。
持久性:Kafka将数据存储在磁盘上,保证数据不会丢掉。
牢靠性:Kafka供给数据仿制和分区机制,保证数据传输的牢靠性。
Kafka广泛使用于日志搜集、实时剖析、事情源等场景。

Flink是由Apache基金会开发的一个开源流处理结构,它供给了高效、牢靠的流处理才能。Flink的中心组件包含:
流处理引擎:用于处理实时数据流。
批处理引擎:用于处理批量数据。
图处理引擎:用于处理大规模图数据。
Flink具有以下特色:
高性能:Flink的流处理引擎在处理实时数据流时具有高性能。
牢靠性:Flink供给数据备份和康复机制,保证数据处理的牢靠性。
易用性:Flink供给丰厚的API和东西,便利用户进行大数据开发。
大数据开源结构为处理和剖析海量数据供给了强壮的支撑。Hadoop、Spark、Kafka和Flink等结构各有特色,适用于不同的场景。用户能够依据实践需求挑选适宜的结构,以进步大数据处理功率。

1.需求剖析:了解事务需求,确认需求存储的数据类型、数据量、数据联系以及查询和陈述需求。2.数据库规划:依据需求剖析成果,规划数据库...
2025-02-26

Oracle数据库中的递归查询是经过WITHRECURSIVE子句完成的。这种查询办法答应你在查询中引证之前界说的查询成果,然后创立递...
2025-02-26

1.核算机科学与技能:这是大数据的中心专业之一,触及核算机体系的规划、开发、保护和操作,以及软件工程、人工智能、数据结构、算法等常识。...
2025-02-26

在数据库中,特点(Attribute)是指表(Table)中的列(Column)。每个特点都有一个称号,它界说了该列所存储的数据的类型。...
2025-02-26

内存型数据库(InMemoryDatabase,IMD)是一种将一切数据存储在内存中的数据库办理体系。与传统的磁盘型数据库比较,内存...
2025-02-26






