打造全能开发者,开启技术无限可能
机器学习中的聚类是一种无监督学习技能,用于将数据会集的方针分组,使得组内的方针互相类似,而组间的方针互相不同。聚类算法能够协助咱们辨认数据中的形式,了解数据的内涵结构,并运用于多种范畴,如商场细分、交际网络剖析、图画处理等。
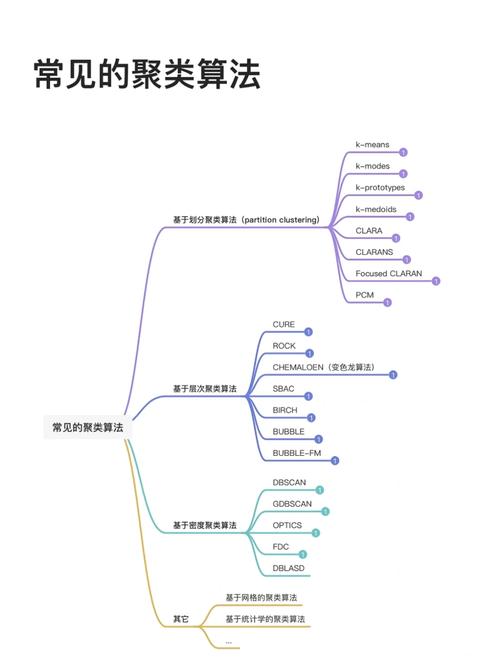
以下是几种常见的聚类算法:
1. KMeans聚类: 原理:挑选K个初始点作为质心,然后分配每个点到一个最近的质心,从头核算质心,重复这个进程直到质心不再改变。 长处:核算简略,易于完成。 缺陷:对初始质心的挑选灵敏,或许堕入部分最优。
2. 层次聚类: 原理:经过构建一棵树来表明数据点的层次联系,能够生成不同粒度的聚类。 长处:能够生成层次化的聚类成果。 缺陷:核算复杂度较高,不适宜大规模数据集。
3. DBSCAN(DensityBased Spatial Clustering of Applications with Noise): 原理:根据密度的聚类,将数据点分为中心点、边界点和噪声点。 长处:能够处理恣意形状的聚类,对噪声和反常值有较好的鲁棒性。 缺陷:参数挑选对成果影响较大。
4. 谱聚类: 原理:运用数据点的邻接矩阵来构建类似性矩阵,经过谱剖析找到数据的低维表明,从而进行聚类。 长处:能够处理非欧几里得空间的数据,适用于高维数据。 缺陷:核算复杂度较高,对参数挑选灵敏。
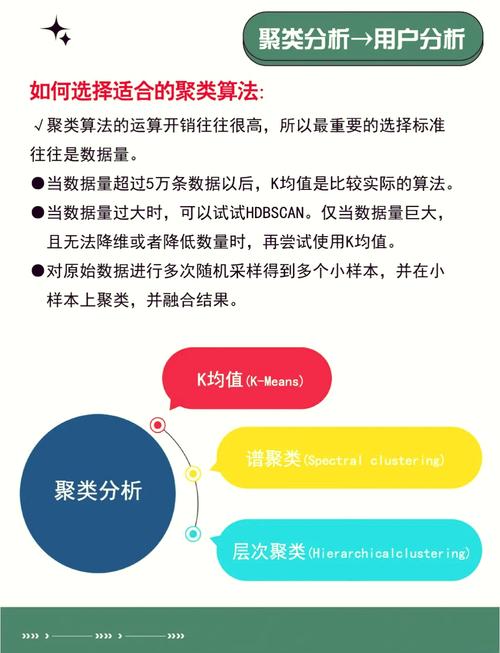
在实践运用中,挑选适宜的聚类算法需求考虑数据的特征、聚类的意图以及核算资源等要素。一起,聚类算法的成果往往依赖于参数的挑选,因此在运用进程中需求进行恰当的参数调整和评价。
聚类剖析是机器学习范畴中的一种无监督学习办法,它经过发掘数据中的内涵结构和规则,将数据方针主动划分为多个类别或簇。本文将深化探讨聚类剖析的基本原理、运用场景以及面临的应战。
聚类剖析的中心思维是将类似的数据点归为一类,而将不同类的数据点区别开来。在聚类剖析中,一般运用间隔衡量来衡量数据点之间的类似性。常见的间隔衡量办法包含欧几里得间隔、曼哈顿间隔等。
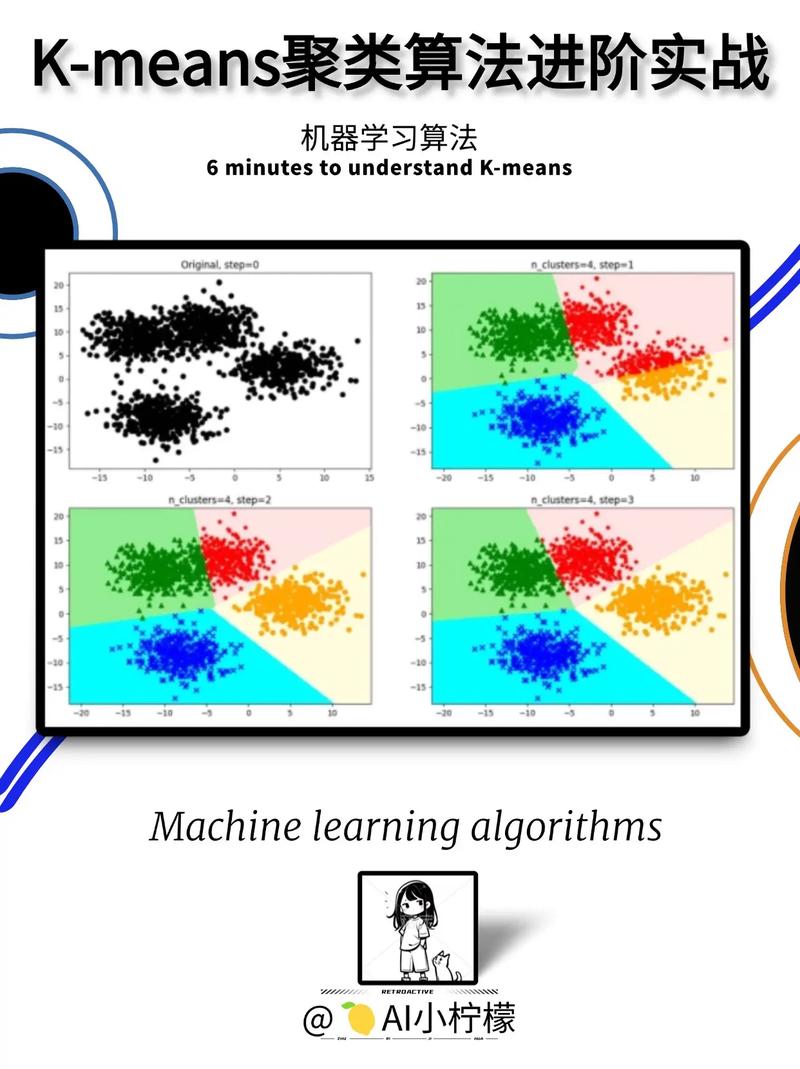
在很多聚类算法中,K-means算法因其简略高效而备受喜爱。K-means算法的基本思维是:经过迭代的办法,将数据划分为K个不同的簇,并使得每个簇内数据点的类似性最大化,而簇间的类似性最小化。
1. 算法原理
方针函数:K-means的方针是最小化以下方针函数:
k:簇的数量。
C:第 i 个簇的调集。
μ:第 i 个簇的中心(质心)。
d(x, μ):样本点 x 到质心 μ 的欧几里得间隔。
过程:
初始化:随机挑选K个初始质心。
分配样本点到最近的质心:将每个样本点分配到最近的簇中心,构成K个簇。
更新质心:核算每个簇中所有样本点的均值,作为新的簇中心。
迭代:重复过程2和3,直到簇中心不再产生明显改变或到达预设迭代次数。
1. 长处:
简略高效:算法简单了解和完成,适宜中小型数据集。
快速收敛:在大多数情况下,K-means收敛速度较快。
2. 缺陷:
需求指定K:聚类数K需求预先指定,或许难以确定。
易受初始点影响:初始质心的挑选或许导致不同的聚类成果。
对反常值灵敏:反常点或许明显影响簇中心的方位。
仅适用于凸簇:不能有用处理非凸形状的簇。
聚类剖析在许多范畴都有着广泛的运用,以下罗列一些常见的运用场景:
商场细分:经过聚类剖析,企业能够更好地了解客户需求,拟定更精准的营销战略。
图画处理:聚类剖析能够用于图画切割、色彩量化等使命。
生物信息学:聚类剖析能够用于基因表达数据的剖析,提醒基因之间的相互作用联系。
交际网络剖析:聚类剖析能够用于辨认交际网络中的紧密联系集体。
1. 聚类不平衡问题:在实践国际中,数据往往存在不平衡现象,这或许导致聚类成果不精确。
2. 高维数据与维度灾祸:高维数据中,数据点之间的间隔衡量变得困难,简单导致聚类成果欠安。
3. 初始质心的挑选:初始质心的挑选对聚类成果有较大影响,怎么挑选适宜的初始质心是一个应战。
聚类剖析是机器学习范畴中一种重要的无监督学习办法,具有广泛的运用远景。在实践运用中,咱们还需求面临各种应战,如聚类不平衡、高维数据等。经过不断优化算法和改善办法,咱们能够更好地发挥聚类剖析在各个范畴的运用价值。

AI大模型的特色包含:1.大规模参数:AI大模型的参数数量一般到达数亿乃至数百亿等级,这使得模型能够学习到更丰厚的形式和常识。2.杂...
2024-12-26

入门书本1.《机器学习》by周志华这本书是机器学习范畴的经典入门教材,掩盖面广,合适初学者作为教材运用。2.《计算学习...
2024-12-26

Artbreeder:答应用户混合和匹配不同的图画来创立新的图画。DeepArt.io:运用深度学习将用户的相片转...
2024-12-26

南洋理工大学(NTU)在机器学习范畴供给了多个课程和研讨方向,以下是详细信息:课程1.信号处理与机器学习硕士课程该课程旨在为...
2024-12-26

AI制造海报是一个相对广泛的概念,它或许涉及到不同的东西和技能。下面我会依据你供给的布景信息,为你供给一些或许的计划。首要,你需求清晰你...
2024-12-26








