打造全能开发者,开启技术无限可能
向量数据库(Vector Database)是一种专门用于存储和检索向量数据的数据库体系。它们在处理高维数据,如文本、图画或音频数据时,一般与机器学习模型(如深度学习模型)结合运用。这些模型能够生成数据的高效表明,称为向量,然后向量数据库能够存储这些向量并供给快速的查找功用。
1. Faiss:由Facebook AI Research开发,是一个库,用于高效类似性查找和密布向量聚类。它不是数据库,但能够与数据库体系结合运用。
2. Annoy:由Spotify开发,是一个小型的、快速的库,用于近似最近邻查找。
3. Elasticsearch:尽管Elasticsearch首要是一个查找引擎,但它也能够用于存储和查找向量数据,尤其是在与Elasticsearch ML插件结合运用时。
4. Milvus:由Zilliz开发,是一个开源的向量数据库,专为存储和查找高维向量数据而规划。
5. Pinecone:一个根据云的向量数据库服务,供给快速、可扩展的向量查找功用。
6. Qdrant:一个开源的向量数据库,由Yandex开发,用于存储和查找高维向量数据。
7. Weaviate:一个开源的向量数据库,专心于语义查找和向量查找。
8. Scai:一个商业化的向量数据库,供给快速的向量查找和可扩展性。
9. RediSearch:由Redis Labs开发,是一个Redis模块,用于完成全文查找和向量查找。
10. Dense Vector Index:由Apache Solr开发,是一个用于存储和查找高维向量的插件。
这些向量数据库体系一般不直接供给大模型,但它们能够与各种机器学习模型结合运用。例如,用户能够运用深度学习模型(如BERT、GPT3等)来生成文本数据的高效表明,然后将这些向量存储在向量数据库中,以便进行快速的查找和检索。

向量数据库是一种专门用于存储和检索高维空间中向量数据的数据库。在大模型年代,向量数据库首要用于存储和检索大模型练习过程中发生的向量数据,如文本、图画、音频等。这些向量数据经过向量化处理后,能够方便地进行类似度核算和检索,然后提巨大模型的功用和功率。
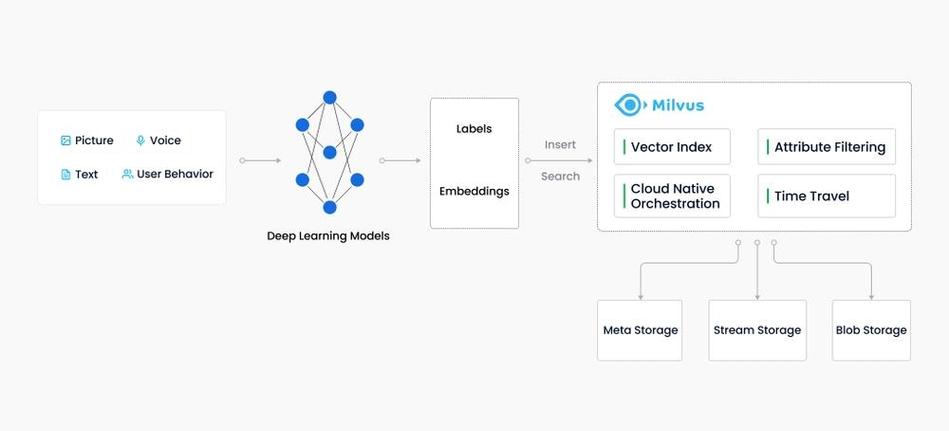
向量数据库在大模型中的使用场景首要包含以下几个方面:
文本检索:经过将文本数据向量化,向量数据库能够快速检索与查询文本类似的内容,使用于查找引擎、问答体系等。
图画辨认:将图画数据向量化后,向量数据库能够用于图画检索、图画分类等使命,如人脸辨认、物体检测等。
语音辨认:语音数据向量化后,向量数据库能够用于语音检索、语音辨认等使命,如语音帮手、语音翻译等。
引荐体系:向量数据库能够用于存储用户行为数据,经过类似度核算为用户供给个性化的引荐内容。
向量数据库在大模型年代具有以下优势:
高效检索:向量数据库选用高效的索引结构,如球树、k-d树等,能够快速检索类似向量。
高精度核算:向量数据库支撑多种类似度核算方法,如余弦类似度、欧氏间隔等,能够确保检索成果的准确性。
可扩展性:向量数据库支撑分布式存储和核算,能够满意大规模数据存储和检索的需求。
安全性:向量数据库支撑数据加密、拜访操控等安全机制,保证数据安全。
跟着大模型技能的不断开展,向量数据库也将呈现出以下开展趋势:
智能化:向量数据库将结合人工智能技能,完成主动索引、主动优化等智能化功用。
多模态交融:向量数据库将支撑多种数据类型的存储和检索,如文本、图画、音频等,完成多模态数据的交融。
云原生:向量数据库将愈加重视云原生架构,供给愈加灵敏、可扩展的云服务。
开源生态:向量数据库将积极参与开源社区,推进开源生态的开展。
向量数据库在大模型年代扮演着中心基础设施的人物。跟着大模型技能的不断开展,向量数据库将发挥越来越重要的效果。了解向量数据库的界说、使用场景、优势和开展趋势,有助于咱们更好地掌握大模型年代的开展脉息。

Oracle数据库支撑多种业务阻隔等级,这些阻隔等级界说了业务之间的相互影响程度。Oracle数据库中的业务阻隔等级首要分为以下几种:1...
2024-12-23

数据库中的1对1联系是指表中的每一条记载只与另一表中的一条记载相相关。这种联系一般用于存储具有特定特点的信息,其间每个特点值只对应一个实...
2024-12-23

云核算和大数据是当今信息技能范畴的重要概念,它们在推进数字化转型和智能化开展方面发挥着关键作用。1.云核算:云核算是一种依据互联网的核...
2024-12-23

云上贵州大数据工业开展有限公司是云上贵州工业服务有限公司的全资子公司,建立于2014年,注册资本为3.35亿元人民币。公司首要致力于推进...
2024-12-23

MySQL是一个开源的联系型数据库办理体系,它由瑞典MySQLAB公司开发,现在归于Oracle公司。MySQL是最盛行的...
2024-12-23









