打造全能开发者,开启技术无限可能
机器学习数据湖是一个会集存储、办理和处理很多数据的体系,用于支撑机器学习模型的练习和布置。它一般包含以下要害组件:
1. 数据存储:数据湖支撑多种数据格局的存储,包含结构化、半结构化和非结构化数据。数据能够存储在Hadoop分布式文件体系(HDFS)、Amazon S3、Azure Data Lake Storage等分布式存储体系中。
2. 数据处理:数据湖供给数据处理东西,如Apache Spark、Hive和Pig,用于对数据进行清洗、转化、剖析和发掘。这些东西能够处理大规模数据集,并支撑分布式核算。
3. 数据办理:数据湖供给数据办理功用,如数据目录、元数据办理和数据办理。这些功用有助于用户发现、了解和办理数据湖中的数据。
4. 机器学习结构:数据湖支撑各种机器学习结构,如TensorFlow、PyTorch和scikitlearn。这些结构能够与数据湖中的数据处理东西集成,用于练习和布置机器学习模型。
5. 可扩展性:数据湖具有可扩展性,能够处理不断添加的数据量。它支撑横向扩展,即添加更多的核算和存储资源来满意需求。
6. 安全性:数据湖供给数据安全功用,如拜访操控、加密和审计。这些功用有助于维护数据湖中的数据免受未经授权的拜访和篡改。
7. 剖析和可视化:数据湖供给剖析和可视化东西,如Tableau、Power BI和QlikView。这些东西能够协助用户从数据湖中提取洞悉,并将其可视化。
机器学习数据湖的优势包含:
会集存储和办理数据,进步数据可用性和可拜访性。 支撑多种数据格局和类型,满意不同机器学习使用的需求。 供给数据处理和剖析东西,简化机器学习模型的练习和布置。 具有可扩展性,能够处理大规模数据集。 供给数据安全功用,维护数据湖中的数据。
总归,机器学习数据湖是一个强壮的体系,能够支撑机器学习模型的练习和布置,进步数据剖析和洞悉的功率。

跟着大数据年代的到来,机器学习在各个范畴的使用日益广泛。为了满意机器学习对海量数据的需求,数据湖作为一种新式的数据存储和办理技能应运而生。本文将讨论机器学习数据湖的概念、优势以及在实践使用中的应战。
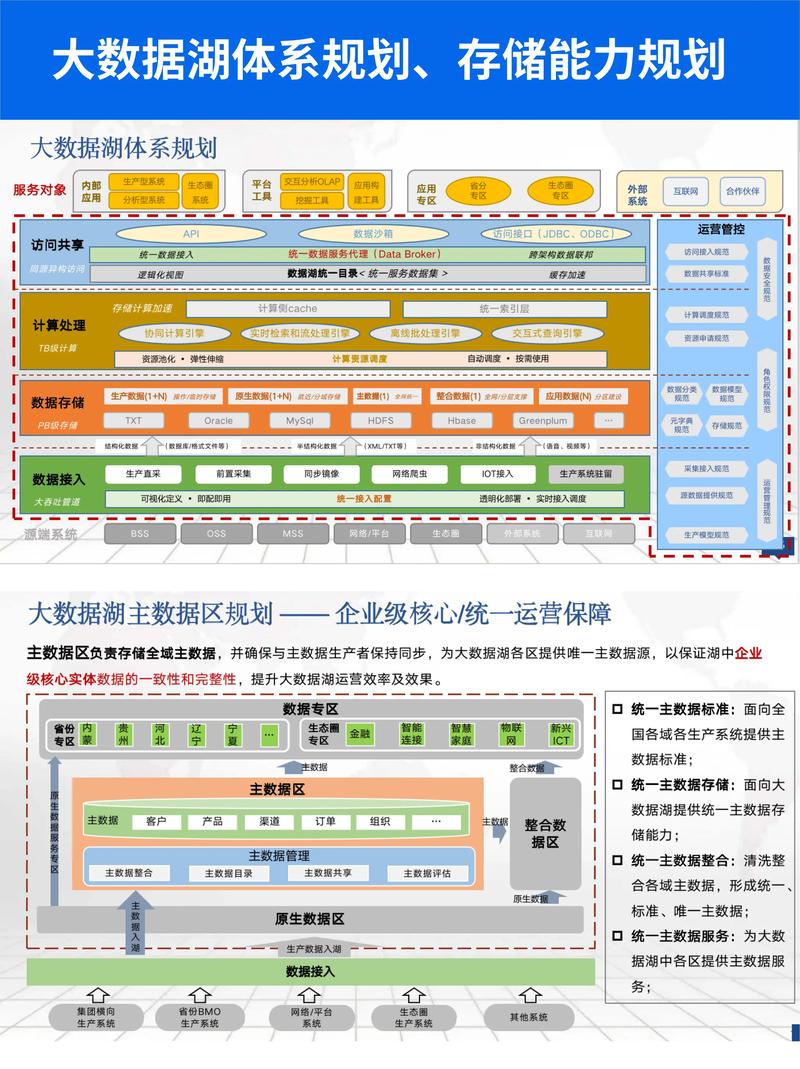
数据湖是一种分布式存储体系,用于存储和办理大规模、多样化的数据。与传统的数据仓库比较,数据湖具有以下特色:
存储格局多样:支撑结构化、半结构化和非结构化数据,如文本、图片、视频等。
数据无需预处理:数据湖中的数据依照原始格局存储,无需进行结构化处理。
弹性扩展:数据湖能够依据需求动态扩展存储空间。
低本钱:数据湖选用分布式存储,降低了存储本钱。

数据湖在机器学习范畴具有以下优势:
数据多样性:数据湖能够存储各种类型的数据,为机器学习供给了丰厚的数据来历。
数据无需预处理:数据湖中的数据无需进行结构化处理,降低了数据预处理的工作量。
高效的数据拜访:数据湖选用分布式存储,进步了数据拜访速度。
灵敏的数据处理:数据湖支撑多种数据处理技能,如批处理、实时处理等。

机器学习数据湖在以下场景中具有广泛的使用:
引荐体系:经过剖析用户行为数据,为用户引荐感兴趣的产品或内容。
诈骗检测:经过剖析买卖数据,辨认潜在的诈骗行为。
智能语音辨认:经过剖析语音数据,完成语音辨认和语音组成。
图画辨认:经过剖析图画数据,完成图画分类和方针检测。
虽然机器学习数据湖具有许多优势,但在实践使用中仍面对以下应战:
数据质量:数据湖中的数据质量良莠不齐,需求树立数据办理机制。
数据安全:数据湖存储了很多敏感数据,需求加强数据安全防护。
数据办理:数据湖中的数据量巨大,需求树立高效的数据办理机制。
技能选型:数据湖触及多种技能,需求依据实践需求进行技能选型。
机器学习数据湖作为一种新式的数据存储和办理技能,在机器学习范畴具有广泛的使用远景。经过处理数据质量、数据安全、数据办理和技能选型等应战,机器学习数据湖将为构建高效数据处理的未来供给有力支撑。
上一篇:机器学习 模型,概述与重要性
下一篇: 机器学习 吴恩达,AI范畴的入门经典

机器学习验证码是一种运用机器学习技能来生成和辨认的验证码。传统的验证码是经过随机生成一系列字符或图画来避免主动化东西进行歹意进犯。跟着机...
2024-12-23

1.言笔AI智能写作软件:言笔AI的实践陈述生成器能够协助用户生成契合标准、内容丰富的陈述。用户只需供给要害信息,AI系统会依...
2024-12-23

猜测模型是机器学习中的一个重要运用,它运用历史数据来猜测未来事情或趋势。以下是猜测模型的一些要害步骤和类型:1.数据搜集:首要,需求搜...
2024-12-23

1.智能客服:经过自然语言处理和机器学习技能,AI可以了解用户的问题并供给相应的答复,进步客户服务的功率和满意度。2.智能引荐:根据...
2024-12-23

多模态AI是指能够了解和处理多种不同类型数据(如文本、图画、音频和视频)的人工智能体系。这种体系能够归纳多种感官信息,然后更全面地了解和...
2024-12-23










