打造全能开发者,开启技术无限可能
机器学习算法有很多种,依据学习办法的不同,能够大致分为以下几类:
1. 监督学习(Supervised Learning):在监督学习中,算法从标示过的练习数据中学习,以便对新的、未见过的数据进行猜测。常见的监督学习算法包含: 线性回归(Linear Regression) 逻辑回归(Logistic Regression) 决议计划树(Decision Trees) 随机森林(Random Forests) 支撑向量机(Support Vector Machines, SVM) 神经网络(Neural Networks) 集成办法(如梯度进步树,GBDT,XGBoost等)
2. 非监督学习(Unsupervised Learning):在非监督学习中,算法从未标示的数据中学习,以发现数据中的形式和结构。常见的非监督学习算法包含: 聚类(Clustering,如KMeans、层次聚类等) 降维(Dimensionality Reduction,如主成分剖析PCA、tSNE等) 相关规则学习(Association Rule Learning,如Apriori算法、Eclat算法等)
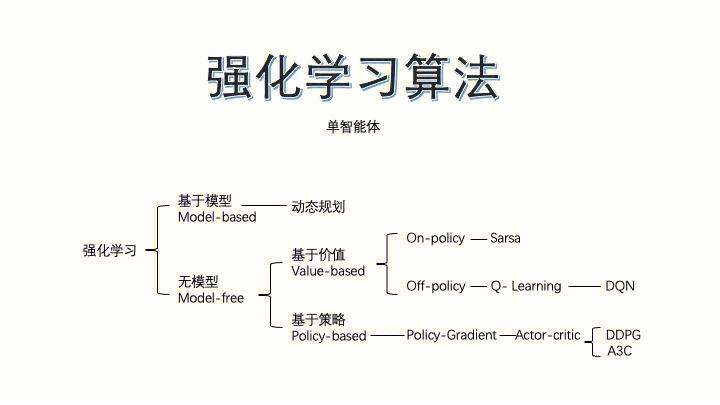
4. 强化学习(Reinforcement Learning):强化学习是一种经过与环境的交互来学习最佳决议计划战略的算法。常见的强化学习算法包含: Q学习(QLearning) 深度Q网络(Deep Q Network, DQN) 战略梯度(Policy Gradient) 艺人评论家办法(ActorCritic Methods)
5. 深度学习(Deep Learning):深度学习是机器学习的一个子范畴,它运用神经网络来学习数据的杂乱表明。常见的深度学习算法包含: 前馈神经网络(Feedforward Neural Networks) 卷积神经网络(Convolutional Neural Networks, CNN) 递归神经网络(Recurrent Neural Networks, RNN) 长短期回忆网络(Long ShortTerm Memory, LSTM) 生成对立网络(Generative Adversarial Networks, GAN)
这些算法在不同的使用场景中发挥着重要作用,挑选适宜的算法取决于具体问题的特色和要求。

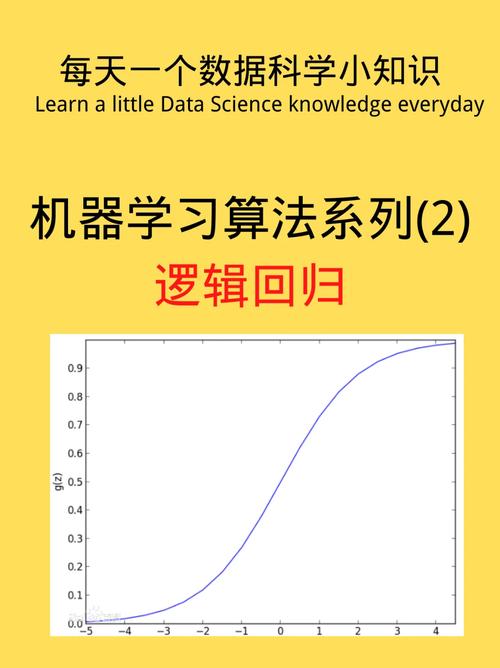
逻辑回归是一种二分类算法,它经过求解逻辑函数来猜测样本归于正类或负类的概率。
决议计划树是一种依据树结构的分类算法,它经过递归地将数据集划分为子集,直到满意中止条件停止。

随机森林是一种集成学习办法,它经过构建多个决议计划树,并对它们的猜测成果进行投票来进步分类和回归的准确性。

支撑向量机是一种二分类算法,它经过找到一个最优的超平面来将数据集划分为两个类别。
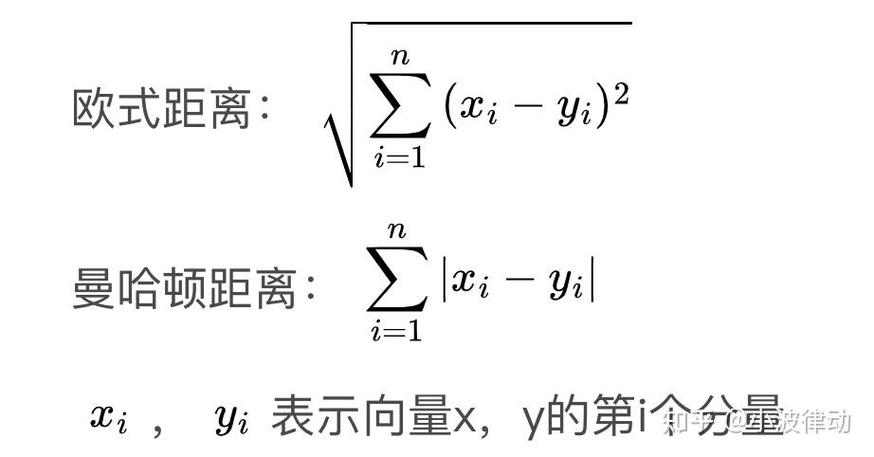

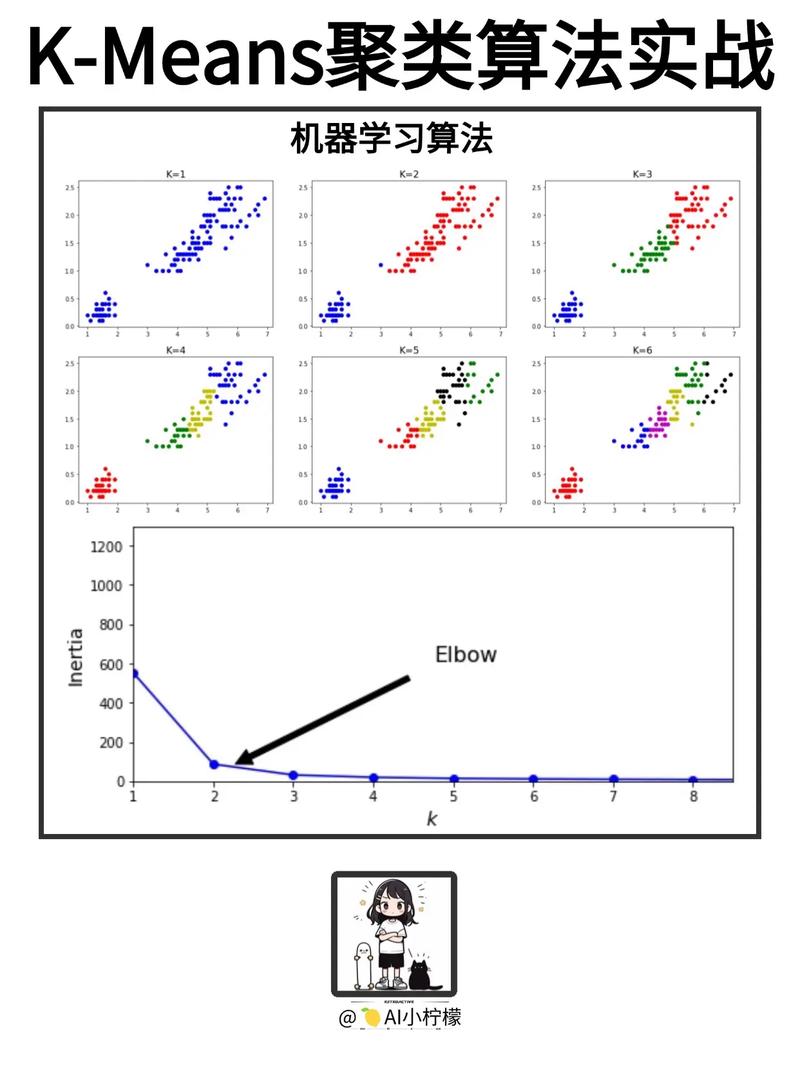
K-means聚类是一种依据间隔的聚类算法,它经过迭代地将数据点分配到最近的聚类中心来构成K个聚类。

聚类层次法是一种依据层次结构的聚类算法,它经过兼并或割裂聚类来构成终究的聚类成果。
主成分剖析是一种降维算法,它经过将数据投影到低维空间来削减数据维度,一起保存大部分信息。

聚类自编码器是一种结合了聚类和自编码器的算法,它经过学习数据表明来一起进行降维和聚类。
自编码器是一种无监督学习算法,它经过学习数据的低维表明来提取特征。

多视图学习是一种处理多源数据的算法,它经过学习数据在不同视图之间的联系来进步模型的功能。

Q-learning是一种依据值函数的强化学习算法,它经过学习Q值来挑选最优动作。
DQN是一种结合了深度学习和Q-learning的算法,它经过神经网络来近似Q值函数。
Policy Gradient是一种依据战略的强化学习算法,它经过优化战略函数来学习最优战略。
机器学习算法品种繁复,本文仅介绍了部分常见的算法。在实践使用中,依据具体问题和数据特色挑选适宜的算法至关重要。期望本文能帮助您更好地了解机器学习算法,为您的项目供给有利的参阅。
下一篇: 微型机器学习,轻量级解决方案的兴起

机器学习验证码是一种运用机器学习技能来生成和辨认的验证码。传统的验证码是经过随机生成一系列字符或图画来避免主动化东西进行歹意进犯。跟着机...
2024-12-23

1.言笔AI智能写作软件:言笔AI的实践陈述生成器能够协助用户生成契合标准、内容丰富的陈述。用户只需供给要害信息,AI系统会依...
2024-12-23

猜测模型是机器学习中的一个重要运用,它运用历史数据来猜测未来事情或趋势。以下是猜测模型的一些要害步骤和类型:1.数据搜集:首要,需求搜...
2024-12-23

1.智能客服:经过自然语言处理和机器学习技能,AI可以了解用户的问题并供给相应的答复,进步客户服务的功率和满意度。2.智能引荐:根据...
2024-12-23

多模态AI是指能够了解和处理多种不同类型数据(如文本、图画、音频和视频)的人工智能体系。这种体系能够归纳多种感官信息,然后更全面地了解和...
2024-12-23










