打造全能开发者,开启技术无限可能
机器学习和强化学习是人工智能范畴的两个重要分支,它们各自有不同的运用场景和优势。
1. 机器学习:机器学习是一种让核算机从数据中学习并做出猜测或决议计划的技能。它依靠于很多数据来练习模型,以便模型能够辨认数据中的形式和规矩。机器学习能够分为监督学习、无监督学习和半监督学习三种类型。
2. 强化学习:强化学习是一种让智能体经过与环境的交互来学习最优战略的技能。它依靠于奖赏机制来辅导智能体的学习进程,使智能体能够最大化其长时间收益。强化学习一般用于处理决议计划问题,如游戏、机器人操控等。
机器学习和强化学习能够彼此弥补,例如,机器学习能够用于练习强化学习中的模型,而强化学习能够用于优化机器学习中的模型参数。在实践运用中,依据问题的特色和需求,能够挑选运用机器学习或强化学习,或许将两者结合起来运用。
1. 机器学习运用: 图像辨认:如人脸辨认、物体辨认等。 自然语言处理:如语音辨认、文本分类等。 引荐体系:如电影引荐、产品引荐等。
2. 强化学习运用: 游戏:如围棋、电子竞技等。 机器人操控:如自动驾驶、机械臂操控等。 资源办理:如电力调度、库存办理等。
总归,机器学习和强化学习是人工智能范畴的重要技能,它们各自有不同的运用场景和优势,能够彼此弥补,为处理各种问题供给强壮的支撑。
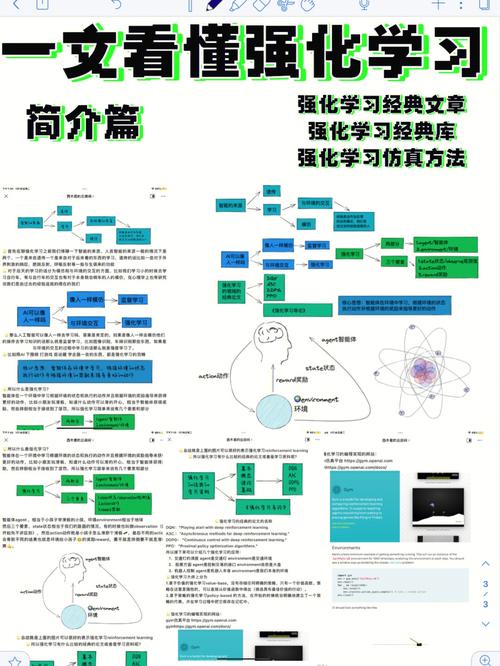
强化学习是一种经过智能体(Agent)与环境的交互来学习最优战略的机器学习方法。在这个进程中,智能体经过不断测验和过错,学习怎么最大化累积奖赏,然后完成智能决议计划。

1. 智能体(Agent):履行动作并与环境交互的主体。
2. 环境(Environment):智能体所在的外部环境,智能体从环境中获取状况和奖赏。
3. 状况(State):描绘环境在某一时间的特征信息。
4. 动作(Action):智能体在某一状况下能够采纳的行为。
5. 奖赏(Reward):环境对智能体某个动作的反应,辅导智能体的学习方针。
6. 战略(Policy):决议智能体在特定状况下挑选动作的规矩。
7. 值函数(Value Function):衡量智能体在某一状况或履行某一动作的长时间报答。
8. 扣头因子(Discount Factor):衡量未来奖赏的重要性。
强化学习的根本结构一般用马尔可夫决议计划进程(Markov Decision Process, MDP)表明。其中心包含:
1. 状况空间(State Space):一切或许的状况调集。
2. 动作空间(Action Space):一切或许动作的调集。
3. 状况搬运概率(State Transition Probability):在某一状况下履行某一动作后,搬运到下一状况的概率。
4. 即时奖赏函数(Immediate Reward Function):智能体履行动作后取得的即时反应。
5. 扣头因子(Discount Factor):衡量未来奖赏的重要性。
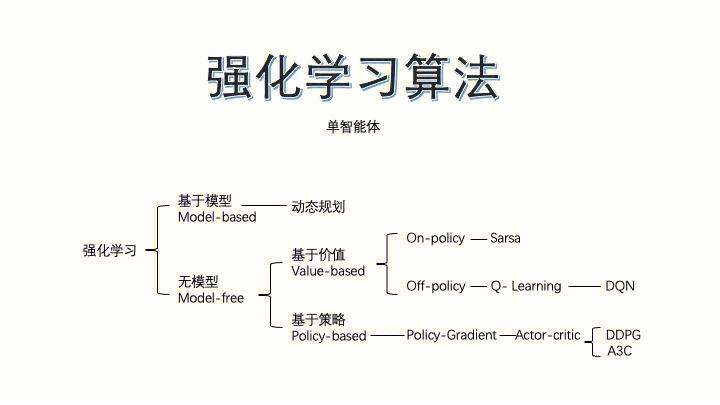
1. Q-Learning:Q-Learning是一种根据值函数的强化学习算法,经过学习状况-动作值函数(Q(s, a))来优化智能体的决议计划才能。
2. SARSA:SARSA是一种根据战略的强化学习算法,经过学习战略来优化智能体的决议计划才能。

1. 长时间依靠问题:强化学习在处理长时间依靠问题时存在困难,需求规划适宜的战略来平衡短期和长时间奖赏。
2. 探究与使用的平衡:在强化学习中,智能体需求在探究不知道状况和使用已知状况之间进行平衡。
3. 核算复杂度:强化学习算法一般需求很多的核算资源,尤其是在处理高维状况空间和动作空间时。
强化学习作为一种强壮的机器学习方法,在智能决议计划范畴具有广泛的运用远景。经过深化了解强化学习的根本概念、中心算法以及在实践运用中的应战,咱们能够更好地发挥其优势,推进人工智能技能的开展。
下一篇: 机器学习在线

机器学习验证码是一种运用机器学习技能来生成和辨认的验证码。传统的验证码是经过随机生成一系列字符或图画来避免主动化东西进行歹意进犯。跟着机...
2024-12-23

1.言笔AI智能写作软件:言笔AI的实践陈述生成器能够协助用户生成契合标准、内容丰富的陈述。用户只需供给要害信息,AI系统会依...
2024-12-23

猜测模型是机器学习中的一个重要运用,它运用历史数据来猜测未来事情或趋势。以下是猜测模型的一些要害步骤和类型:1.数据搜集:首要,需求搜...
2024-12-23

1.智能客服:经过自然语言处理和机器学习技能,AI可以了解用户的问题并供给相应的答复,进步客户服务的功率和满意度。2.智能引荐:根据...
2024-12-23

多模态AI是指能够了解和处理多种不同类型数据(如文本、图画、音频和视频)的人工智能体系。这种体系能够归纳多种感官信息,然后更全面地了解和...
2024-12-23










