打造全能开发者,开启技术无限可能
Apache Pig是一个用于处理和剖析大规模数据集的编程结构,它是Apache Hadoop生态系统的一部分。以下是关于Pig的一些要害特色和优势:
1. 数据流言语和履行环境: Pig包含两部分:Pig Latin(一种描绘数据流的高档言语)和Pig履行环境(用于运转Pig Latin程序的履行渠道)。
2. 面向进程的言语: Pig是一种面向进程的数据流言语,适用于实时剖析场n3. 高效和轻量级: Pig规划为轻量级,履行功率较高,合适需求快速处理很多数据的场合。
4. Pig Latin言语: Pig Latin是一种相似于SQL的言语,用户能够运用它来编写数据处理和转化使命。这种言语简练易用,使得编程愈加直观。
5. 主动优化: Pig的使命会主动进行优化,程序员只需求重视言语的语义,而不需求深化重视底层完成细节。
6. 丰厚的运算符集: Pig供给了丰厚的运算符,如join、sort、filter等,使得数据处理愈加灵敏和高效。
7. 与Hadoop的集成: Pig能够与Hadoop无缝集成,它将杂乱的MapReduce使命简化为Pig Latin脚本,使得非专业的Hadoop开发者也能高效地处理大规模数据集。
8. 适用场n经过这些特色,Apache Pig简化了大数据处理的杂乱性,让数据剖析师和开发人员能够更专心于事务逻辑而非技能细节。


Pig是由Apache Hadoop项目开发的一种高档数据流言语,用于简化Hadoop中的数据转化。它答使用户运用相似SQL的查询言语(Pig Latin)来处理大规模数据集。Pig的首要意图是将杂乱的数据处理使命转化为简略的数据流操作,然后下降编程难度,进步数据处理功率。
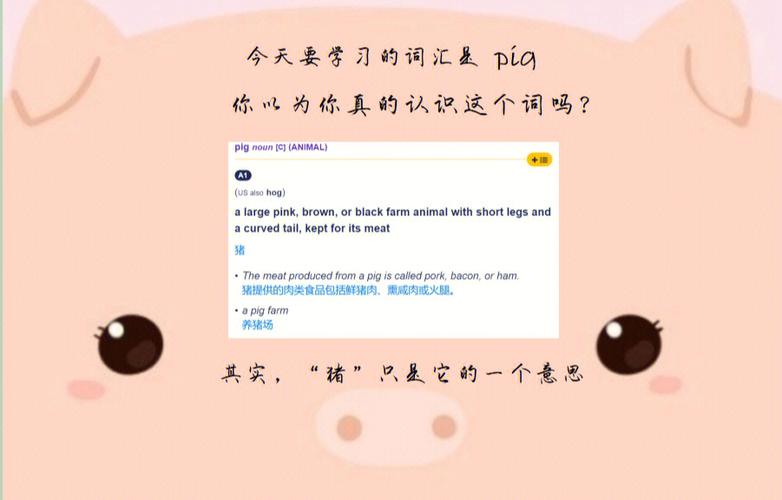
Pig具有以下特色与优势:
易用性:Pig Latin语法简略,易于学习和运用。
高效性:Pig能够高效地处理大规模数据集,进步数据处理速度。
可扩展性:Pig能够与Hadoop生态系统中的其他东西无缝集成,如Hive、HBase等。
灵敏性:Pig支撑多种数据源,如文本文件、联系数据库等。

Pig在以下场景中具有广泛的使用:
数据清洗:Pig能够快速处理很多数据,进行数据清洗和预处理。
数据转化:Pig能够将不同格局的数据转化为一致的格局,便利后续处理。
数据发掘:Pig能够用于数据发掘,发现数据中的潜在价值。
机器学习:Pig能够与机器学习算法结合,完成大规模数据集的机器学习使命。
Pig是Hadoop生态系统中的重要组成部分,与Hadoop严密相连。Pig Latin编写的脚本能够在Hadoop集群上运转,充分利用Hadoop的分布式核算才能。Pig与Hadoop的联系如下:
Pig Latin脚本被编译成MapReduce作业,由Hadoop履行。
Pig支撑多种数据存储格局,如HDFS、HBase、Hive等,能够与Hadoop生态系统中的其他东西协同作业。
Pig能够优化MapReduce作业,进步数据处理功率。

跟着大数据技能的不断发展,Pig在未来将出现以下发展趋势:
功用优化:Pig将持续优化其功用,进步数据处理速度。
功用扩展:Pig将添加更多功用,如支撑更多数据源、更杂乱的查询操作等。
与其他大数据技能的交融:Pig将与更多大数据技能交融,如机器学习、人工智能等。
Pig作为一种高效的大数据处理东西,在当今大数据年代具有广泛的使用远景。跟着技能的不断发展,Pig将在数据处理范畴发挥越来越重要的效果。了解Pig的特色、使用场景和发展趋势,有助于咱们更好地应对大数据年代的应战。

Oracle数据库支撑多种业务阻隔等级,这些阻隔等级界说了业务之间的相互影响程度。Oracle数据库中的业务阻隔等级首要分为以下几种:1...
2024-12-23

数据库中的1对1联系是指表中的每一条记载只与另一表中的一条记载相相关。这种联系一般用于存储具有特定特点的信息,其间每个特点值只对应一个实...
2024-12-23

云核算和大数据是当今信息技能范畴的重要概念,它们在推进数字化转型和智能化开展方面发挥着关键作用。1.云核算:云核算是一种依据互联网的核...
2024-12-23

云上贵州大数据工业开展有限公司是云上贵州工业服务有限公司的全资子公司,建立于2014年,注册资本为3.35亿元人民币。公司首要致力于推进...
2024-12-23

MySQL是一个开源的联系型数据库办理体系,它由瑞典MySQLAB公司开发,现在归于Oracle公司。MySQL是最盛行的...
2024-12-23









