打造全能开发者,开启技术无限可能
Faiss(Facebook AI Similarity Search)是一个由Facebook AI Research团队开发的开源库,用于高效处理大规划高维向量数据的类似性查找和聚类。以下是Faiss的入门教程,绵亘装置、根本运用和一些要害概念。
一、Faiss简介Faiss是一款专门为处理高维向量数据而规划的东西,可以高效地履行大规划数据的类似性查找。它支撑多种索引类型和间隔答理方法,而且可以运用GPU进行加快核算。
二、装置Faiss供给CPU和GPU两个版别,依据你的需求挑选装置: CPU版:`pip install faisscpu` GPU版:`pip install faissgpu`
三、根本运用 1. 特征向量的获取特征向量一般经过模型(如BERT)从原始数据(如文本)中提取。例如,关于文本数据,可以运用BERT模型将文本转换为向量表明。
2. 间隔答理算法Faiss支撑多种间隔答理算法,绵亘: L2欧几里得间隔 内积(类似度核算) 余弦类似度。
3. 检索算法Faiss供给两种首要的检索算法: 暴力检索:对一切向量两两进行比较,时刻复杂度为O。 近似最近邻查找(ANNS):经过聚类、降维或编码等技能,将查找规划缩小,进步检索功率。
四、Python示例以下是一个简略的Python示例,展现怎么运用Faiss进行向量检索:```pythonimport numpy as npimport faiss
生成随机向量d = 128 向量维度nb = 10000 向量数量np.random.seedxb = np.random.rand.astype
创立索引index = faiss.IndexFlatL2 运用L2间隔index.add 增加向量
查询向量xq = np.random.rand.astypek = 5 查询最近邻的数量D, I = index.search 回来间隔和索引
printprint```
五、高档功用 1. 索引类型Faiss支撑多种索引类型,如: 倒排索引(IVF) 积量化(PQ) HNSW(Hierarchical Navigable Small World Graph)。
2. GPU加快Faiss可以运用GPU加快向量核算,经过CUDA完成大规划并行处理,极大提高检索功率。
六、应用场n 七、学习资源
经过以上内容,你应该对Faiss的根本概念和运用方法有了开始的了解。假如你有更多具体问题,欢迎持续发问。
Faiss向量数据库入门教程
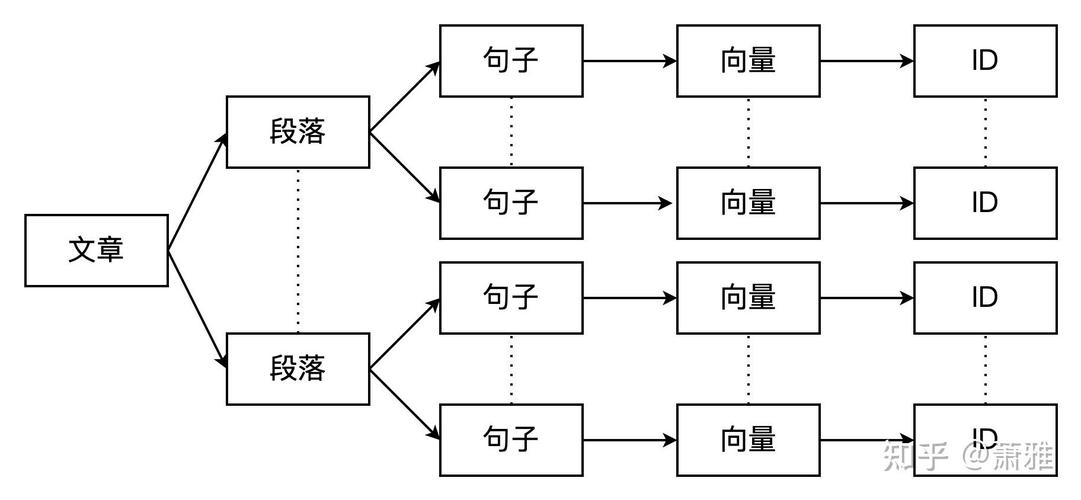
Faiss(Facebook AI Similarity Search)是由Facebook AI Research开发的一个高效的类似性查找库。它首要用于大规划向量数据的类似性查找和聚类,特别合适处理高维数据,如图画特征、文本嵌入等。
挑选Faiss的原因有许多,以下是几个要害点:
高效性:Faiss采用了多种高效的算法和数据结构,可以快速进行最近邻查找(Nearest Neighbor Search),即便在大规划数据集上也能坚持较好的功能。
支撑多种索引类型:Faiss供给了多种索引结构,绵亘平面索引、倒排索引、HNSW和PQ等,合适不同规划和类型的数据。
灵活性:Faiss支撑多种数据类型,绵亘浮点数和二进制数据。
易于集成:Faiss易于与其他机器学习库和结构集成,如TensorFlow、PyTorch等。
以下是装置Faiss的过程:
1. 装置依靠
在装置Faiss之前,需求保证已装置以下依靠项:
CMake
Python
NumPy
OpenBLAS
2. 编译源码
以下是编译Faiss源码的过程:
下载Faiss源码:从GitHub(https://github.com/facebookresearch/faiss)下载Faiss源码。
创立构建目录:在源码目录下创立一个名为“build”的目录。
进入构建目录:翻开指令行窗口,进入“build”目录。
编译Faiss:运转以下指令编译Faiss:
cmake ..
make
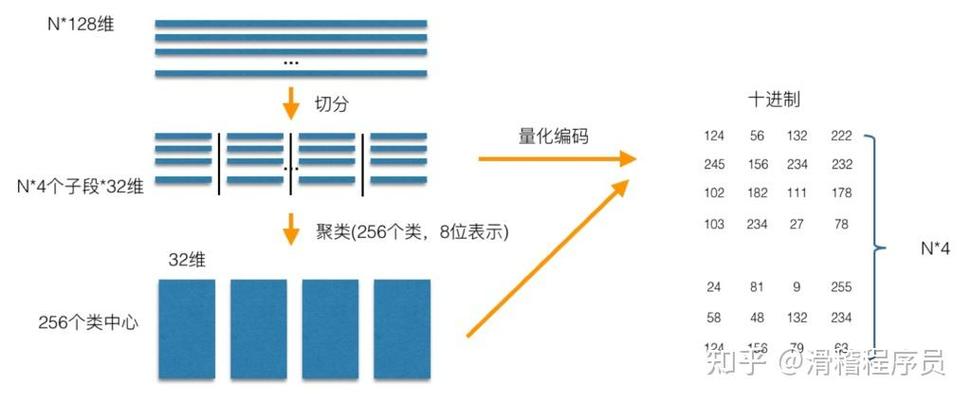
以下是运用Faiss进行类似性查找的过程:
1. 创立索引
首要,需求创立一个索引目标,用于存储向量数据。以下是一个创立平面索引的示例:

大数据是指无法在必定时间内用惯例软件东西进行捕捉、办理和处理的数据调集。它具有很多(Volume)、高速(Velocity)、多样(Va...
2024-12-25

MySQL伪列(PseudoColumns)是一种特别的列,它们并不存储在表中的数据,而是由数据库办理体系(DBMS)在查询时动态生...
2024-12-25

登录MySQL数据库一般运用以下指令:```bashmysqluusernamep```这儿`u`参数后边跟着的是你的MySQ...
2024-12-25

要运用ODBC衔接Oracle数据库,您需求保证现已装置了Oracle的ODBC驱动程序,而且现已装备了数据源(DSN)。以下是一个根本...
2024-12-25

1.线下面授训练:费用一般在2万至3万人民币之间。例如,一些训练组织供给的线下脱产全日制训练费用大约在2万至2.5万人民币。...
2024-12-25








