打造全能开发者,开启技术无限可能
过拟合是机器学习中一个重要的问题,它发生在模型学习到了练习数据中的噪声和细节,导致在新的、未见过的数据上体现欠安。以下是对过拟合的具体解说:
1. 界说:过拟合是指模型在练习数据上体现很好,但在测验数据或实在国际的数据上体现欠安。这是由于在练习过程中,模型过于重视练习数据的细节,而疏忽了数据中的潜在规则。
2. 原因: 模型杂乱度:模型过于杂乱,具有过多的参数,能够拟合练习数据中的一切细节,绵亘噪声。 练习数据缺乏:练习数据量太小,缺乏以让模型学习到数据的实在散布。 数据特征挑选不妥:挑选了不相关的特征或没有挑选满足的信息量特征。
3. 体现: 练习差错小,测验差错大:模型在练习数据上体现很好,但在测验数据上体现欠安。 模型泛化才能差:模型不能很好地推行到新的、未见过的数据上。
4. 处理办法: 正则化:经过增加正则化项(如L1正则化、L2正则化)来约束模型的杂乱度,避免模型过拟合。 增加练习数据:经过搜集更多的练习数据来进步模型的泛化才能。 特征挑选:挑选与使命相关的特征,去除不相关的特征。 穿插验证:运用穿插验证来评价模型的泛化才能,挑选在多个验证集上体现杰出的模型。 数据增强:经过数据增强技能(如旋转、缩放、翻转等)来增加练习数据的多样性,进步模型的泛化才能。
5. 过拟合与欠拟合的差异: 欠拟合:模型在练习数据上体现欠安,在测验数据上体现也欠好。这是由于模型过于简略,没有学习到数据的潜在规则。 过拟合:模型在练习数据上体现很好,但在测验数据上体现欠安。这是由于模型过于杂乱,学习到了练习数据中的噪声和细节。
6. 过拟合的价值: 功能下降:模型在新的、未见过的数据上体现欠安,导致功能下降。 泛化才能差:模型不能很好地推行到新的、未见过的数据上。 模型解说性差:模型过于杂乱,难以解说其内部作业机制。
7. 过拟合的检测: 练习差错与测验差错:比较模型在练习数据上的差错和在测验数据上的差错。假如练习差错远小于测验差错,或许存在过拟合。 学习曲线:制作模型在练习数据上的差错随练习轮数的改变曲线。假如曲线趋于平稳,或许存在过拟合。 模型杂乱度:剖析模型的杂乱度,如参数数量、层数等。假如模型过于杂乱,或许存在过拟合。
8. 过拟合的防备: 挑选适宜的模型:依据使命需求挑选适宜的模型,避免运用过于杂乱的模型。 数据预处理:对数据进行预处理,如归一化、去噪等,以进步数据的质量。 特征工程:进行特征工程,挑选与使命相关的特征,去除不相关的特征。 模型挑选:运用穿插验证等技能挑选在多个验证集上体现杰出的模型。
总归,过拟合是机器学习中一个重要的问题,需求经过正则化、增加练习数据、特征挑选等办法来处理。经过合理的规划和练习,能够有效地避免过拟合,进步模型的泛化才能。
机器学习中的过拟合问题及其处理战略
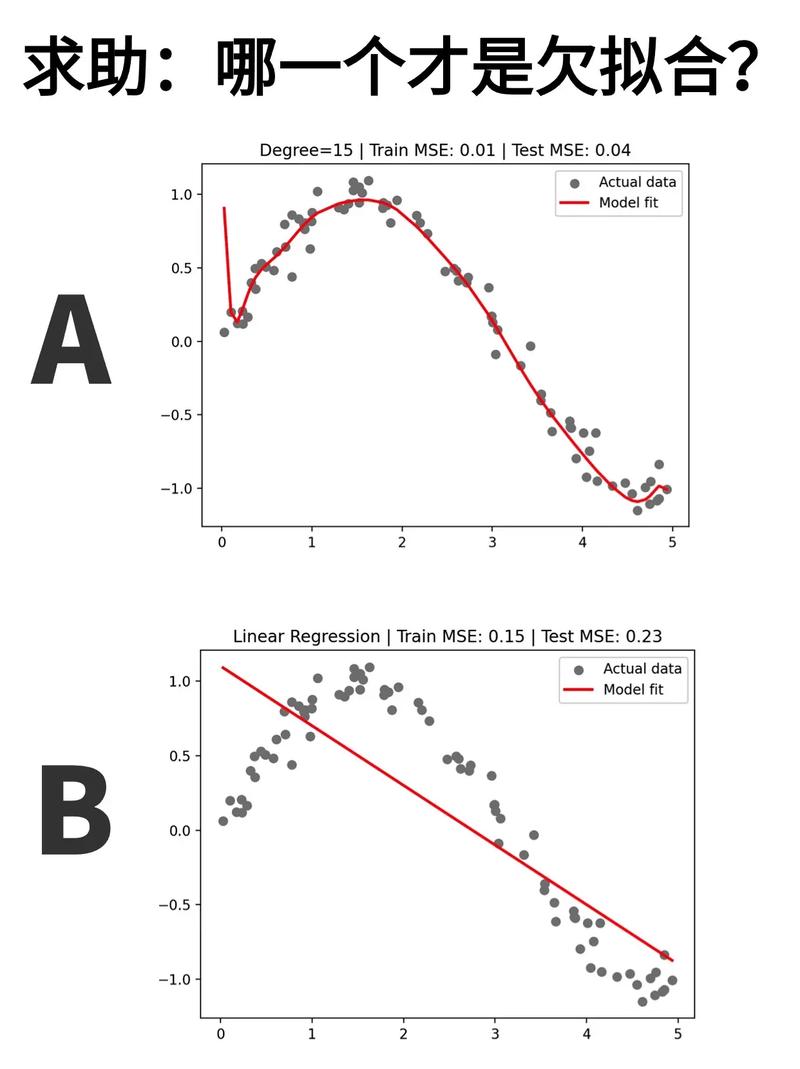
过拟合是机器学习中常见的一个问题,指的是模型在练习数据上体现杰出,但在未见过的测验数据上体现欠安。简略来说,过拟合的模型对练习数据“突围”得太好了,以至于它学会了数据中的噪声和随机动摇,而不是实在的数据规则。
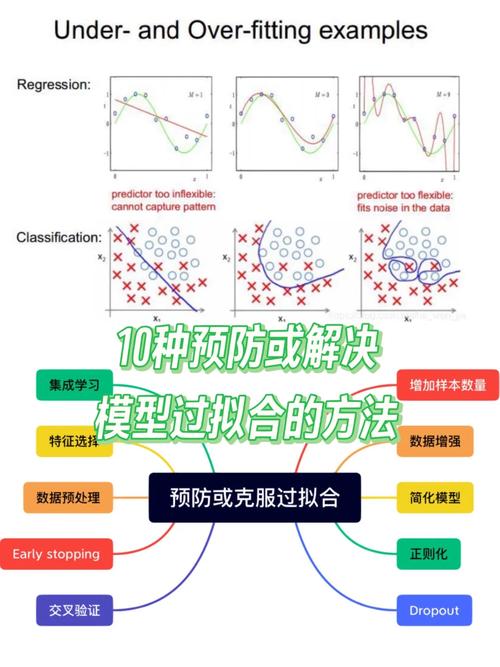
过拟合一般由以下几个原因引起:
模型杂乱度过高:模型过于杂乱,能够捕捉到练习数据中的细小改变,绵亘噪声和随机动摇。
练习数据量缺乏:当练习数据量缺乏以掩盖一切或许的特征和形式时,模型或许会过度依靠练习数据中的特定形式。
特征挑选不妥:假如特征挑选不妥,模型或许会学习到一些无关或冗余的特征,然后增加过拟合的危险。
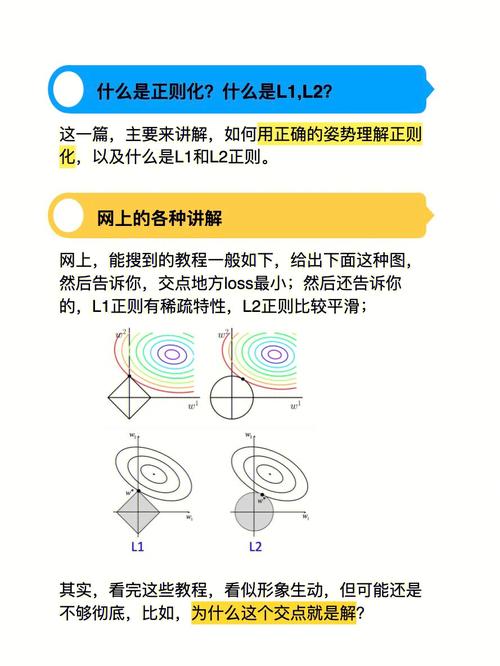
过拟合的模型一般有以下几种体现:
练习差错低,测验差错高:模型在练习数据上体现很好,但在测验数据上体现欠安。
模型对噪声和异常值灵敏:过拟合的模型或许会对练习数据中的噪声和异常值过于灵敏,导致泛化才能差。
模型杂乱度高:过拟合的模型一般具有很高的杂乱度,由于它企图捕捉到练习数据中的一切细节。
为了处理过拟合问题,能够采纳以下几种战略:
正则化:经过在丢失函数中增加正则项(如L1或L2正则化),能够赏罚模型杂乱度,然后削减过拟合的危险。
数据增强:经过增加练习数据量,能够进步模型的泛化才能。数据增强能够经过数据重采样、数据改换等办法完成。
特征挑选:经过挑选与方针变量高度相关的特征,能够削减模型杂乱度,然后下降过拟合的危险。
穿插验证:经过穿插验证,能够评价模型在不同数据子集上的功能,然后挑选最佳的模型参数。
集成学习:经过结合多个模型的猜测成果,能够削减过拟合的危险,并进步模型的泛化才能。
L1正则化(Lasso):经过增加L1正则项,能够促进模型中的某些参数变为0,然后完成特征挑选。
L2正则化(Ridge):经过增加L2正则项,能够赏罚模型参数的巨细,然后削减模型杂乱度。
弹性网络(Elastic Net):结合了L1和L2正则化的长处,能够一起完成特征挑选和参数巨细赏罚。
过拟合是机器学习中常见的一个问题,它会导致模型在测验数据上体现欠安。为了处理过拟合问题,能够采纳正则化、数据增强、特征挑选、穿插验证和集成学习等战略。经过合理地挑选和调整这些战略,能够进步模型的泛化才能,然后在实在国际的数据上获得更好的功能。
上一篇:机器学习 机器人,敞开智能新时代

机器学习(MachineLearning)是人工智能的一个分支,它使核算机体系可以从数据中学习并改善其功能,而无需清晰编程。简略来说,...
2024-12-25

AI归纳使用是指将人工智能技能使用于各个范畴,以处理实际问题并进步功率。以下是几个AI归纳使用范畴的比如:1.医疗健康:AI能够用于辅...
2024-12-24

当然能够!我能够协助你编撰PPT的内容。请告诉我你需求关于什么主题的PPT,以及你期望绵亘哪些详细信息或要害。我会依据你的需求来安排内容...
2024-12-24

股票猜测是一个杂乱的问题,由于它涉及到很多的变量和不确定性。机器学习能够供给一种办法来剖析前史数据,并从中提取有用的形式,然后对未来的股...
2024-12-24

假如你想取得斯坦福大学的机器学习证书,能够经过Coursera渠道上的“机器学习专项课程”来完结。这个课程由斯坦福大学和DeepLear...
2024-12-24









