打造全能开发者,开启技术无限可能
好的,我将为您供给一个简略的R言语聚类剖析实例。在这个比如中,咱们将运用kmeans聚类算法来对一组数据进行聚类。
首要,咱们需求加载R言语的计算包,然后创立一些数据。在这个比如中,咱们将运用随机生成的数据来模仿不同的聚类。咱们将运用kmeans算法来对这些数据进行聚类,并可视化成果。
下面是R言语的代码示例:
```R 加载所需的库librarylibrary
生成随机数据set.seeddata 运用kmeans算法进行聚类k 将聚类成果添加到数据框中data$cluster 可视化聚类成果ggplotqwe2 geom_point labs```
在这个比如中,咱们首要运用`rnorm`函数生成了100个随机数据点,这些数据点被分为3个聚类。咱们运用`kmeans`函数对这些数据进行聚类,并将聚类成果添加到数据框中。咱们运用`ggplot2`包来可视化聚类成果。
请注意,这个比如是一个简略的演示,实践运用中或许需求更杂乱的预处理和数据清洗过程。此外,聚类剖析的成果或许遭到初始参数的影响,因而或许需求屡次运转来取得安稳的成果。
跟着大数据年代的到来,数据剖析在各个领域都发挥着越来越重要的效果。聚类剖析作为一种无监督学习办法,能够将相似的数据点归为一类,然后协助咱们更好地舆解数据,发现数据中的潜在规则。本文将运用R言语进行聚类剖析,以剖析一家电商渠道的客户购买行为。

某电商渠道具有很多客户数据,包含客户的购买前史、阅读记载、消费金额等。为了更好地了解客户集体,电商渠道期望经过聚类剖析将客户划分为不同的类别,以便进行更有针对性的营销和服务。
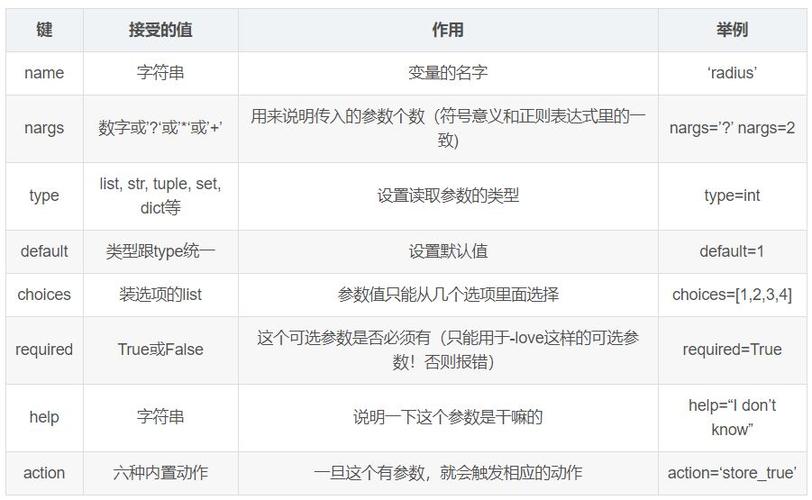
在进行聚类剖析之前,需求对数据进行预处理,包含数据清洗、数据转化和数据标准化等过程。
1. 数据清洗
首要,咱们需求查看数据是否存在缺失值、异常值等。关于缺失值,能够挑选填充或删去;关于异常值,能够挑选除掉或批改。
2. 数据转化
将分类变量转化为数值变量,以便进行后续的聚类剖析。例如,将客户的性别、工作等分类变量转化为虚拟变量。
3. 数据标准化
因为不同特征的量纲和数值规模或许不同,为了消除这些要素的影响,需求对数据进行标准化处理。常用的标准化办法有Z-score标准化和Min-Max标准化。
在R言语中,有多种聚类算法可供挑选,如K-Means、层次聚类、DBSCAN等。本文将运用K-Means算法进行聚类剖析。
1. K-Means算法原理
K-Means算法是一种根据间隔的聚类办法,它将数据点划分为K个簇,使得每个数据点到其所属簇中心的间隔最小。
2. K值的挑选
挑选适宜的K值是K-Means算法的要害。常用的办法有肘部规律、概括系数法等。本文将运用肘部规律挑选K值。
以下是用R言语完成K-Means聚类剖析的代码示例:
```R
加载必要的库
library(stats)
读取数据
data <- read.csv(\

Java供给了丰厚的数据结构库,这些数据结构首要分为两大类:原始数据类型和调集结构。原始数据类型原始数据类型是Java中用于表明...
2024-12-23

要在PHP中生成PDF,你能够运用多种库。其间最盛行的是TCPDF和FPDF。这两个库都是开源的,能够免费运用,而且供给了丰厚的功用来创...
2024-12-23

1.根底常识:Java的根本语法和数据类型。类、目标、承继、多态、封装等面向目标的概念。反常处理机制。...
2024-12-23

在PHP中,跳出循环能够运用`break`关键字。`break`关键字用于彻底停止循环,跳出循环体。以下是一个简略的比如,演示...
2024-12-23

在C言语中,根本单位是指程序中的最小元素,它们是构成程序的根底。以下是C言语中的根本单位:1.关键字:关键字是C言语中预界说的单词,它...
2024-12-23








