打造全能开发者,开启技术无限可能
机器学习模型一般绵亘以下几个进程来运转:
1. 数据预备:首要需求搜集和预备数据,这绵亘数据清洗、数据转化和数据归一化等。数据质量对模型的功能至关重要。
2. 挑选模型:根据问题的类型(如分类、回归、聚类等)挑选适宜的机器学习算法。常用的算法绵亘线性回归、决策树、支撑向量机、神经网络等。
3. 练习模型:运用预备好的数据来练习模型。练习进程触及调整模型的参数,使其能够从数据中学习并做出精确的猜测。
4. 评价模型:在练习完结后,运用测验数据集来评价模型的功能。这能够经过核算精确率、召回率、F1分数等目标来完结。
5. 调整模型:根据评价成果,或许需求对模型进行进一步的调整,如调整参数、添加或削减特征等,以进步模型的功能。
6. 布置模型:一旦模型到达满足的功能,就能够将其布置到出产环境中,用于实践的数据剖析和猜测。
7. 监控和保护:模型布置后,需求定时监控其功能,并根据需求进行保护和更新,以保证其继续有用。
请注意,这仅仅一个大致的结构,详细的进程或许会因问题的性质、数据的特色和所运用的东西而有所不同。

在运转机器学习模型之前,首要需求建立一个适宜的环境。以下是建立环境的根本进程:
挑选适宜的操作体系:Windows、Linux或macOS均可,但Linux体系在运转深度学习模型时功能更佳。
装置Python:Python是机器学习的首要编程言语,需求装置Python解说器和pip包管理器。
装置必要的库:根据所运用的机器学习结构(如TensorFlow、PyTorch等),装置相应的库和依靠项。
装备GPU支撑:假如运用GPU加快,需求装置CUDA和cuDNN等驱动程序。
数据是机器学习模型的根底,预备高质量的数据关于模型的功能至关重要。以下是数据预备的根本进程:
数据搜集:根据模型需求,从各种渠道搜集数据,如揭露数据集、数据库或传感器数据。
数据清洗:对搜集到的数据进行清洗,去除噪声、缺失值和异常值。
数据预处理:对数据进行标准化、归一化等处理,以便模型更好地学习。
数据区分:将数据区分为练习集、验证集和测验集,用于模型练习、验证和评价。
在数据预备完结后,接下来便是模型练习环节。以下是模型练习的根本进程:
挑选模型架构:根据问题类型和数据特色,挑选适宜的模型架构,如神经网络、决策树等。
装备模型参数:设置模型的超参数,如学习率、批巨细、迭代次数等。
练习模型:运用练习集对模型进行练习,不断调整模型参数以优化功能。
验证模型:运用验证集评价模型功能,调整超参数以避免过拟合。
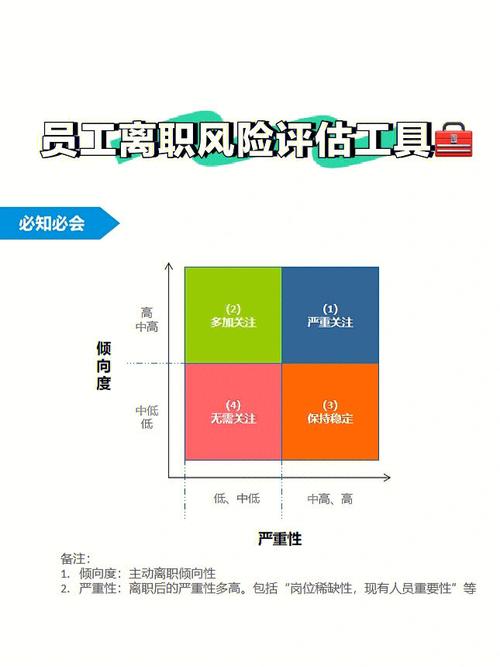
模型练习完结后,需求对其功能进行评价。以下是模型评价的根本进程:
挑选评价目标:根据问题类型和数据特色,挑选适宜的评价目标,如精确率、召回率、F1值等。
核算评价目标:运用测验集核算模型的评价目标,以评价模型功能。
剖析成果:剖析评价目标,了解模型的优缺点,为后续优化供给根据。

在评价模型功能后,假如发现模型存在缺乏,需求进行优化。以下是模型优化的根本进程:
调整模型架构:测验不同的模型架构,以寻觅更适合问题的模型。
调整超参数:调整模型的超参数,如学习率、批巨细、迭代次数等,以优化模型功能。
数据增强:对练习数据进行增强,进步模型的泛化才能。
穿插验证:运用穿插验证办法,进一步评价模型功能。
运转一个机器学习模型需求阅历多个进程,绵亘环境建立、数据预备、模型练习、评价和优化。经过本文的介绍,信任读者现已对机器学习模型的运转进程有了根本的了解。在实践使用中,不断优化和调整模型,以进步其功能和泛化才能。

1.周志华教授亲授:知乎专栏《启蒙教师周志华亲身解说!机器学习视频课上线了!》介绍了周志华教授主讲的《机器学习开端》课程,运用...
2024-12-25

1.云工网云工网供给机器学习兼职接单招聘渠道,数千名优异在线全职兼职开发外包接单,包含电商、网站、APP等。机器学习3天免费试...
2024-12-25

徐亦达教授是悉尼科技大学(UTS)全球数据技能中心的机器学习和数据剖析试验室主任,首要研讨方向包含机器学习、数据剖析和计算机视觉。他在世...
2024-12-25

1.AI东西网网站链接:特征:汇集了超越800种国内外AI人工智能东西,包含智能对话、AI绘画、构思写作、多语言翻...
2024-12-25

1.ROS(RobotOperatingSystem):ROS是一个开源的机器人操作体系,供给了丰厚的东西和库,用于开发、...
2024-12-25










