打造全能开发者,开启技术无限可能
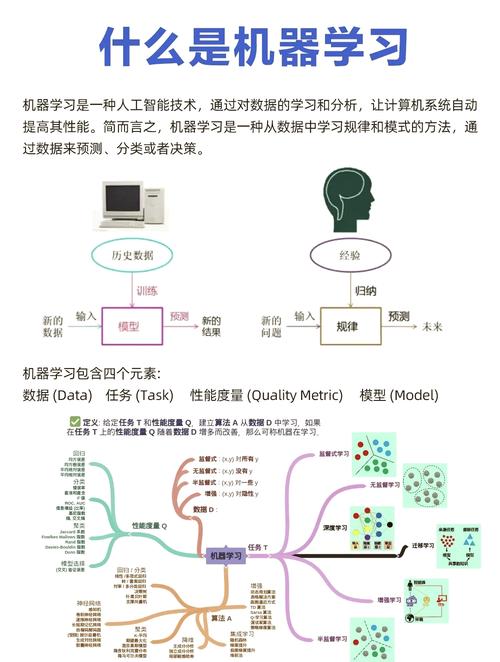
机器学习数据剖析项目一般包含以下几个进程:
1. 问题界说:清晰项目方针,确认需求处理的问题。这包含了解事务需求、清晰项目规模和预期作用。
2. 数据搜集:依据问题界说,搜集相关数据。数据能够来自多种来历,如数据库、API、文件等。
3. 数据预处理:对搜集到的数据进行清洗、转化和归一化。这包含处理缺失值、异常值、重复数据等。
4. 特征工程:从原始数据中提取或创立新的特征,以增强模型的学习才能。
5. 模型挑选:依据问题类型(如分类、回归、聚类等)挑选适宜的机器学习模型。
6. 模型练习:运用练习数据集对模型进行练习,调整模型参数以优化功能。
7. 模型评价:运用验证数据集或测试数据集评价模型的功能,包含精确率、召回率、F1分数等方针。
8. 模型布置:将练习好的模型布置到出产环境中,以便在实践运用中运用。
9. 监控和保护:对布置的模型进行监控,保证其功能安稳。依据需求进行模型更新或从头练习。
在整个项目进程中,需求运用各种东西和技能,如Python、R、SQL、数据可视化东西、机器学习库(如scikitlearn、TensorFlow、PyTorch)等。此外,还需求考虑数据隐私、安全性和合规性等问题。
跟着大数据年代的到来,机器学习在数据剖析中的运用越来越广泛。本文将具体介绍一个机器学习数据剖析项目的实战进程,包含数据预处理、特征工程、模型挑选、练习与评价等关键进程。
项目布景:某电商渠道期望经过剖析用户购买行为数据,猜测用户是否会购买某款产品,然后完成精准营销。
项目方针:构建一个机器学习模型,能够精确猜测用户购买行为,进步营销作用。
数据预处理是机器学习项目中的关键进程,它包含数据清洗、数据转化和数据集成等。
1. 数据清洗
在数据清洗阶段,咱们需求处理缺失值、异常值和重复值等问题。
(1)缺失值处理:关于缺失值,咱们能够选用填充、删去或插值等办法进行处理。
(2)异常值处理:经过可视化或计算办法辨认异常值,并对其进行处理。
(3)重复值处理:删去重复数据,防止模型过拟合。
2. 数据转化
数据转化包含数值型数据转化和类别型数据转化。
(1)数值型数据转化:对数值型数据进行标准化、归一化或离散化处理。
3. 数据集成
将预处理后的数据集进行整合,为后续建模做准备。

特征工程是进步模型功能的关键环节,它包含特征挑选、特征提取和特征组合等。
1. 特征挑选
经过计算办法、模型挑选或递归特征消除等办法,挑选对模型猜测有重要影响的特征。
2. 特征提取
从原始数据中提取新的特征,进步模型的猜测才能。
3. 特征组合
将多个特征组合成新的特征,以增强模型的猜测才能。

依据项目需求和数据特色,挑选适宜的机器学习模型,并进行练习。
1. 模型挑选
依据项目布景和方针,挑选适宜的机器学习模型,如逻辑回归、决策树、支撑向量机、随机森林等。
2. 模型练习
运用预处理后的数据集对模型进行练习,调整模型参数,进步模型功能。
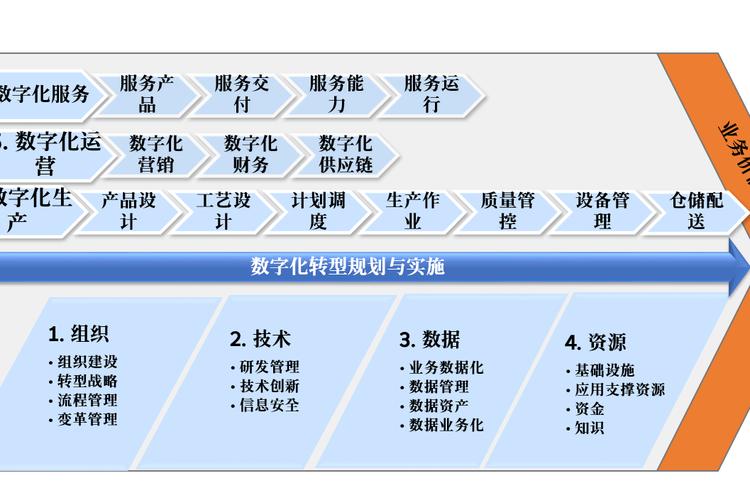
对练习好的模型进行评价,并依据评价成果进行优化。
1. 模型评价
运用穿插验证、混杂矩阵、ROC曲线等办法对模型进行评价。
2. 模型优化
依据评价成果,调整模型参数或测验其他模型,以进步模型功能。
本文具体介绍了机器学习数据剖析项目的实战进程,从数据预处理到模型评价,每个进程都进行了具体论述。经过实践操作,咱们能够更好地了解机器学习在数据剖析中的运用,为后续项目供给参阅。
下一篇: 机器学习专业,未来科技浪潮中的灿烂明珠

机器学习验证码是一种运用机器学习技能来生成和辨认的验证码。传统的验证码是经过随机生成一系列字符或图画来避免主动化东西进行歹意进犯。跟着机...
2024-12-23

1.言笔AI智能写作软件:言笔AI的实践陈述生成器能够协助用户生成契合标准、内容丰富的陈述。用户只需供给要害信息,AI系统会依...
2024-12-23

猜测模型是机器学习中的一个重要运用,它运用历史数据来猜测未来事情或趋势。以下是猜测模型的一些要害步骤和类型:1.数据搜集:首要,需求搜...
2024-12-23

1.智能客服:经过自然语言处理和机器学习技能,AI可以了解用户的问题并供给相应的答复,进步客户服务的功率和满意度。2.智能引荐:根据...
2024-12-23

多模态AI是指能够了解和处理多种不同类型数据(如文本、图画、音频和视频)的人工智能体系。这种体系能够归纳多种感官信息,然后更全面地了解和...
2024-12-23










